说明
本书旨在记录并完善嵌入式面试过程中可能遇到的八股文相关的问题。其中“八股文”主要指面试过程中经常被问到的、有固定答案或固定格式答案的问题,也可以简单地理解为面经1。
本书内容不采用基础知识+测试题目的方式组织,而是使用问答的方式进行组织。因为采用前一种方式,还不如直接读教材;采用后一种方式主要是为了查漏补缺。本文收集的问题及答案难以避免地会引用网络上其他博主的免费内容,针对这类问题及答案,笔者会尽量补齐内容的出处。如有遗漏欢迎指正,多谢!
如果对本文有任何问题,可以在书籍所在的GitHub仓库Issues模块或Discussion模块直接提出,多谢!
另外提一句,笔者并不认可这种“八股文”面试的形式,不过打不过也只能加入了。 🙈
C语言基础语法知识
-
C语言有哪些
存储类型(Storage Class)?参考答案
存储类型主要定义程序对象(变量及函数)的存储生命周期及作用域;C语言的四种存储类型及其生命周期和作用域分别为:
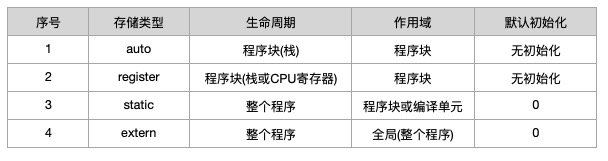
register修饰符有特殊的限制,具体如下:objects declared with the register storage class may be given higher priority by the compiler for access to registers; although the compiler may choose not to actually store any of them in a register. Objects with this storage class may not be used with the address-of (&) unary operator.即使用
register修饰的变量,会优先存储在CPU寄存器中(但不一定会存储在寄存器中,因为寄存器数量是有限的),而且该变量不能使用取地址符(&);参考资料:
-
C语言中
static关键字有哪些作用?参考答案
static修饰符可用于修饰全局变量、局部变量或函数,三种场景下的作用分别为:- 修饰全局变量时:被修饰的变量称为静态全局变量。该全局变量仅在当前文件内可见。
- 修饰局部变量时:被修饰的变量称为静态局部变量。变量仅初始化一次,而且由于变量是存储在数据段,而非堆或栈上,因此局部变量在离开作用域后不会被销毁,变量值始终有效直至程序结束。
- 修饰函数时:被修饰的函数称为静态函数。该函数仅在当前文件内可见。
参考资料:
-
是否可以在头文件中定义
static变量?参考答案
可以,但包含该头文件的源文件会有命名相同但实际不同的
static变量。参考资料:
-
volatile的作用是什么,什么时候需要使用volatile?参考答案
volatile修饰变量时表示变量的值可能有多个途径进行修改,尽管在代码上并没有显式修改变量值。因此volatile用于指示编译器针对所修饰的变量不要进行编译优化,防止编译器优化导致变量值的读写异常。举个简单的例子,以下代码中全局静态变量
b不使用volatile修饰:static int b; int main() { b = 1; while (b != 255) { ; } return 0; }其生成的二进制如下(使用gcc -O3):
Disassembly of section __TEXT,__text: 0000000000000000 <_main>: 0: 55 pushq %rbp 1: 48 89 e5 movq %rsp, %rbp 4: 66 2e 0f 1f 84 00 00 00 00 00 nopw %cs:(%rax,%rax) e: 66 90 nop 10: eb fe jmp 0x10 <_main+0x10>而加上
volatile修饰之后的,其二进制如下:Disassembly of section __TEXT,__text: 0000000000000000 <_main>: 0: 55 pushq %rbp 1: 48 89 e5 movq %rsp, %rbp 4: c7 05 fc ff ff ff 01 00 00 00 movl $1, -4(%rip) ## 0xa <_main+0xa> e: 66 90 nop 10: 8b 05 00 00 00 00 movl (%rip), %eax ## 0x16 <_main+0x16> 16: 3d ff 00 00 00 cmpl $255, %eax 1b: 75 f3 jne 0x10 <_main+0x10> 1d: 31 c0 xorl %eax, %eax 1f: 5d popq %rbp 20: c3 retq从生成的不同的二进制我们可以看到,不加
volatile修饰时,并没有比较b和255的值,即代码优化导致实际的代码逻辑出现异常。参考资料:
-
inline和macro在使用上有什么区别?参考答案
inline和macro均可以用于做代码的替换,这两者的差别主要有:- 代码展开的阶段不同。
macro在预处理阶段就进行展开,而inline在代码编译过程展开。 - 类型检查的要求不同。
macro并不做类型检查,而inline函数本身就是函数,会做类型检查。 - 表达式计算的方式不同。
macro可能会对表达式进行多次运算,而inline函数仅在表达式传入函数时进行运算。如#define sum(a, b) (a) + (b)和inline func(int a, int b) { return a + b; }分别使用sum(a++)和func(a++, b)进行调用时,前者a++计算了两次,而后者a++仅计算一次。
针对
inline需要注意的是:inline只是建议编译器对函数进行内联展开,编译器并不一定会采纳。- 在支持热补丁的场景下,采用
inline可能是一个bad idea。
参考资料:
- 代码展开的阶段不同。
-
什么是
Segmentation Fault,什么时候会出现,如何避免?参考答案
Segmentation Fault中文译为段错误,出现段错误主要是因为程序访问到无权限访问的内存区域。常见的段错误场景主要有:- 对空指针(NULL/nullptr)或未初始化的指针(指针可能指向无效地址)进行解引用(dereference)
- 数组越界访问
- 对只读区域的内存进行更新或访问无效/无权限的内存区域(如内核态地址空间)
避免段错误可以考虑使用静态代码扫描工具,如PC-lint等,扫描代码是否存在以下问题:
- 指针变量未初始化
- 数组是否可能存在越界访问
参考资料:
-
const int* p,int* const p,const int* const p这三者有什么区别?参考答案
const int* p中const修饰的是*p,即指针p所指的对象。也就是说p的值是可以变化的(指向的地址可以变化),但*p不可以(指向的值不可以变化)。如下:
int main() { int a = 1; int b = 2; const int* p = &a; p = &b; // ok *p = 3; // error return 0; }int* const p中const修饰的是p,即指针p。也就是说p的值是不可以变化的(指向的地址不可以变化),但*p可以(指向的值可以变化)。如下:
int main() { int a = 1; int b = 2; int* const p = &a; *p = 2; // ok p = &b; // error return 0; }const int* const p中const既修饰指针p,也修饰针对所指的地址中的内容*p。即指针p不可变化,且指针所指向的地址中的值*p也不可变化。如下:
int main() { int a = 1; int b = 2; const int* const p = &a; *p = 2; // error p = &b; // error return 0; } -
extern "C"的作用是什么?参考答案
extern C主要用于C++程序中,作用于程序的链接过程。如果接触过C++会知道C++支持函数的重载。即如下C++代码的定义是允许的:int func(int a) { return a + 1; } long func(long b) { return b + 2; } int main() { func(1); // call func(int a) func(1L); // call func(long b) return 0; }为支持重载功能,编译器在解析函数时使用函数名及形参类型改编形成新的函数签名,从而保证两个重载函数拥有不同的符号,该过程称为
name mangling。如上面代码生成的二进制代码中,两个重载函数的实际名称分别为:__Z4funci和__Z4funcl:eric% nm a.out 0000000100003f50 T __Z4funci 0000000100003f60 T __Z4funcl 0000000100000000 T __mh_execute_header 0000000100003f80 T _main U dyld_stub_binder其中
__Z表示该符号名称是被C++编译器改编的,而Z后面的数字4指实际函数名称(func)为4个字符。然而C程序中不支持重载,即函数命名是怎样的,其在二进制中看到的就是怎样的。如下为
func函数在二进制中的符号:eric % nm a.out 0000000100000000 T __mh_execute_header 0000000100003f80 T _func 0000000100003f90 T _main U dyld_stub_binder其中
_func中的前缀_为C语言调用约定(C calling convention)要求。因此,若要在C++程序中调用C代码,就需要将被调用函数声明在
extern C中,表示所调用的函数遵循C语言调用约定。否则编译过程会出现符号找不到问题。参考资料:
-
什么是字节对齐(数据结构对齐)?
参考答案
在C语言中,数据结构对齐主要用于结构体定义中。现代CPU在数据结构对齐的前提下可以获得更好的读写效率。数据结构对齐的定义是:
若内存地址`a`是`n`的倍数(其中`n`是2的幂),那么`a`就是n字节对齐的。C程序在x86构架上对不同类型的字节对齐有不同的要求,以64位x86架构为例:
1个char类型(1个字节长度)为`1字节对齐` 1个short类型(2个字节长度)为`2字节对齐` 1个int类型(4个字节长度)为`4字节对齐` 1个long类型(8个字节长度)为`8字节对齐` 1个floag类型(4个字节长度)为`4字节对齐` 1个double类型(8个字节长度)为`8字节对齐` 1个指针类型(8个字节长度)为`8字节对齐`也即如果有如下结构体,其结构体大小在64位x86上应该为
24个字节:struct s { char a; // 1 byte // 1 byte padding short b; // 2 bytes char c; // 1 byte // 3 bytes padding int d; // 4 bytes float e; // 4 bytes double f; // 8 bytes };在上面的结构体中,成员
a是1字节对齐的,而成员b是2字节对齐的,因此在a和b中,会自动添加空白的padding用于保证字节对齐。同理c是1字节对齐的,而d是4字节对齐的,因此在c和d间会自动添加3个padding。如果想修改自动对齐方式,可以在结构体定义前添加
#pragma pack(N),其中N为N字节对齐。如下将struct s修改为1字节对齐后,其结构体大小为20字节:#pragma pack(1) struct s { char a; short b; char c; int d; float e; double f; };参考资料:
-
什么是内存泄漏?
参考答案
C程序中允许使用
malloc等函数在堆上申请内存,这部分内存是需要开发人员自行管理的,若申请的内存一直未释放或无法释放,最后会导致堆可用的空间越来越少,严重的会导致程序崩溃。常见的内存泄漏原因是申请了内存,但内存不再使用后却不释放。如下C代码中申请的内存a在退出函数时未释放,该情境即为内存泄漏场景:void func() { int *t = malloc(1000); }避免内存泄漏主要有以下几种方法:
- 代码检视
- 代码静态扫描工具
- 工具检测,如valgrind
参考资料:
-
大端小端是什么意思?如何判断当前CPU是大端还是小端?
参考答案
大端模式(Big-endian)是指数据的高字节保存在内存的低地址而数据的低字节保存在内存的高地址。大端模式有点类似于字符串的存储方式——内存的地址从低到高,而数据从高到低存放。 小端模式(Little-endian)是指数据的高字节保存在内存的高地址而数据的低字节保存在内存的低地址。 之所以存在大小端模式,是因为我们的内存中每个地址单位对应一个字节(即8bit),但C语言中的
short类型、int类型等是由多个字节组成的,对于16bit及以上的CPU来说,在处理这类多字节类型时就存在字节的组织问题。 要判断CPU使用大端还是小端可以直接解析short类型中低地址的值是高字节还是低字节,代码如下:#include <stdio.h> int main() { short a = 1; printf("a is %s\n", *((char*)&a) == 0x1 ? "little-endian" : "big-endian"); return 0; }需要注意的是,不同的架构可能使用不同的大小端模式,如x86架构为小端模式,arm架构默认为小端模式,但也可以切换为大端模式。
参考资料:
-
如何判断两个浮点数是否相等?
参考答案
在C语言中,与浮点数相关的有两种类型:
float及double,前者为单精度类型,后者为双精度类型。(float及double类型的存储方式可参考IEEE标准的规定) 由于浮点数的数据存储方式,在运算过程中可能存在精度问题,如下:#include <stdio.h> int main() { double a = 0.15 + 0.15; double b = 0.10 + 0.20; printf("a(%lf) is %s to b(%lf)\n", a, a == b ? "euqal" : "not euqal", b); return 0; }上面代码的实际运行结果为:
a(0.300000) is not euqal to b(0.300000)在实际程序中,
a和b的二进制表示分别如下:a: 0011 1111 1101 0011 0011 0011 0011 0011 0011 0011 0011 0011 0011 0011 0011 0011 b: 0011 1111 1101 0011 0011 0011 0011 0011 0011 0011 0011 0011 0011 0011 0011 0100我们可以看到,即使
a和b都是0.3,但在小数部分的最后3 bit实际上是有差异的。为了解决这类浮点数的比较问题,我们可以人为规定一个精度,当精度小于某个确定的值后可以近似地认为两个浮点数相等。在标准库的float.h头文件中就提供了精度宏:FLT_EPSILON及DBL_EPSILON分别代表float类型的精度及double类型的精度,修改后的浮点数比较代码如下:#include <stdio.h> #include <float.h> #include <math.h> int main() { double a = 0.15 + 0.15; double b = 0.10 + 0.20; printf("a(%lf) is %s to b(%lf)\n", a, fabs(a - b) < DBL_EPSILON ? "euqal" : "not euqal", b); printBits(a); printBits(b); return 0; }参考资料:
-
typedef和#define的区别?参考答案
#define和typedef均可用于定义类型别名。但其区别有:#define作用于编译过程的预处理阶段而typedef作用于编译阶段typedef仅用于定义类型别名,而#define还可以定义常量、代码块等
参考资料:
-
malloc和free的实现原理?参考答案(答案来源于ChatGpt)
malloc和free是C语言中用于动态内存管理的函数。malloc函数用于在运行时动态分配指定大小的内存块。它的实现原理通常涉及底层的内存分配算法,例如堆(heap)管理。以下是一种常见的实现原理:-
malloc的实现原理:malloc函数接收一个参数,即所需内存块的大小。malloc会在堆中寻找一块足够大的连续内存空间。- 当找到合适的空间后,它会记录该块内存的大小并进行标记,以便稍后的内存释放使用。
- 返回指向该内存块的指针,供程序使用。
-
free的实现原理:free函数接收一个指针参数,即要释放的内存块的起始地址。free会根据传入的指针找到对应的内存块,并将该内存块标记为可用。- 释放的内存块可以被后续的
malloc调用重新分配使用。
实际的
malloc和free实现可能会因操作系统、编译器和特定的堆管理器而有所不同。这些函数的底层实现通常涉及内存分配算法、堆的数据结构和管理机制。需要注意的是,使用
malloc分配的内存需要在不再需要时使用free显式释放,以避免内存泄漏。如果不释放已分配的内存,会导致程序的内存消耗不断增加,最终可能导致系统资源不足的问题。参考资料:
-
-
请解释C语言中的条件语句
if-else和switch-case的用法和区别。参考答案(答案来源于ChatGpt)
if-else用法:if-else语句用于根据一个条件的真假执行相应的代码块。如果条件为真,执行if后面的代码块;如果条件为假,执行else后面的代码块(如果有)switch-case用法:switch-case语句用于根据一个表达式的值,从多个选项中选择一个执行相应的代码块。
区别:
if-else语句用于对条件的真假进行判断。switch-case语句用于对一个表达式的不同取值进行判断。
-
什么是指针数组和数组指针?请解释它们之间的区别。
参考答案
- 指针数组的英文为:
array of pointers,它表示一个元素都是指针类型的数组。 - 数组指针的英文为:
pointers to an array,它表示一个指向数组的指针
- 指针数组的英文为:
C语言堆与线相关知识
-
函数调用过程是如何压栈及出栈的?
参考答案
每个函数都有一段空间,存储其入参、本地变量及其它临时变量(如函数返回地址等),该段空间称为函数调用栈(call stack)。调用栈是一个栈数据结构,其维护由程序自行处理。 函数调用过程的压栈、出栈的具体操作与操作系统及CPU架构相关,下面介绍一般过程:
- 保存寄存器中的函数返回地址(caller的下一条语句的执行地址)、栈顶地址到栈上
- 栈顶指针偏移(由高地址向低地址移动)
- 入参压栈
- 局部变量压栈
- 执行函数代码
- 退出时恢复caller的函数返回地址、栈顶指针地址到寄存器中
参考资料:
-
解释堆栈溢出(Stack Overflow)是什么,以及如何避免它发生?
参考答案
堆栈溢出(Stack Overflow)是一种常见的编程错误,指的是当一个程序在执行过程中使用了太多的堆栈空间,导致堆栈内存溢出,无法继续正常执行。
堆栈溢出通常发生在以下几种情况下:
- 递归调用:递归函数在没有正确的终止条件或者递归深度过大的情况下,会导致堆栈溢出。每次递归调用都会创建一个新的堆栈帧,当递归深度过大时,堆栈空间会被耗尽。
- 大规模的局部变量:如果一个函数中定义了过多的局部变量,这些变量会占用大量的堆栈空间,导致堆栈溢出。
为了避免堆栈溢出,可以采取以下几种措施:
- 优化递归算法:确保递归函数有正确的终止条件,避免无限递归。可以考虑使用迭代代替递归,或者采用尾递归优化等技术减少堆栈空间的使用。
- 减少局部变量的使用:尽量避免在函数中定义过多的局部变量,可以考虑将一些变量声明为全局变量或静态变量,或者使用动态内存分配(如堆内存)来存储大规模的数据。
- 增加堆栈空间的限制:在某些编程语言中,可以通过配置编译器或运行时环境来增加堆栈的大小限制,以便为程序提供更多的堆栈空间。
- 使用动态内存分配:对于需要大量内存的操作,可以考虑使用动态内存分配(如malloc或new)来分配堆内存,而不是使用堆栈空间。
- 代码审查和测试:进行代码审查和全面的测试,以发现潜在的堆栈溢出问题。尽早发现并修复这些问题可以避免在运行时出现堆栈溢出错误。
-
什么是栈指针(Stack Pointer)?它的作用是什么?
参考答案
栈指针(Stack Pointer)是一种特殊的指针,用于指示程序在执行过程中的当前堆栈位置。它指向堆栈顶部或下一个可用的堆栈位置。栈指针的具体实现方式依赖于硬件架构和操作系统。
栈指针在程序执行期间起到了关键作用,用于维护函数调用和局部变量的管理。它具有以下几个主要的作用:
- 函数调用:当一个函数被调用时,当前函数的返回地址和其他相关的上下文信息(如参数值等)会被推入堆栈中,栈指针会相应地向下(低地址)移动。
- 局部变量的分配和释放:当函数中定义局部变量时,这些变量的空间会在堆栈中被分配。栈指针会根据变量的大小移动到适当的位置来为局部变量分配内存。当函数执行完毕或局部变量不再需要时,栈指针会回退到前一个位置,释放相应的内存空间。
- 堆栈帧的管理:每当一个函数被调用时,一个新的堆栈帧(stack frame)会被创建并被推入堆栈中。堆栈帧包含了函数的参数、局部变量和返回地址等信息。栈指针用于定位当前堆栈帧的位置,以便正确地管理函数调用和返回。
-
如何在嵌入式系统中检查和调试堆栈问题?
参考答案
在嵌入式系统中检查和调试堆栈问题可以采用以下方法:
- 使用日志和调试输出:通过在关键位置插入日志语句或调试输出语句,记录堆栈状态和相关信息,以便跟踪问题。可以使用串口输出、调试端口或其他适配的输出方式来查看日志。
- 堆栈监视器:某些嵌入式系统提供硬件或软件堆栈监视器。这些监视器可以实时监测堆栈的状态,包括栈指针的变化和堆栈溢出。具体实现和使用方法会根据嵌入式系统的硬件和工具链而有所不同。
- 断言(Assertions):在关键位置使用断言来检查堆栈状态是否符合预期。断言是一种在代码中插入的检查语句,如果条件不满足,则会触发断言失败,进而中断程序执行,以便进行调试。
- 动态内存分析工具:使用适用于嵌入式系统的动态内存分析工具可以帮助检测和调试堆栈问题,例如MemCheck、Valgrind等。这些工具可以跟踪内存分配和释放操作,检测内存泄漏和堆栈溢出等问题。
- 静态代码分析工具:使用静态代码分析工具可以检查代码中的潜在堆栈问题,例如递归调用没有终止条件、局部变量超出作用域等。常用的静态代码分析工具包括Lint工具。
- 使用硬件调试器:连接硬件调试器可以提供更详细和准确的堆栈信息。通过硬件调试器,可以实时查看和修改栈指针的值,观察堆栈帧的状态,并跟踪函数调用和返回的路径。
需要注意的是,出于信息安全考虑,第1种方法需要关注是否会涉及敏感信息及软件安全。
-
什么是堆栈大小(Stack Size)?如何确定适当的堆栈大小?
参考答案
堆栈大小(Stack Size)是指为程序执行期间所需的堆栈空间分配的大小。堆栈用于存储函数调用、局部变量和其他相关的上下文信息。以下是确定适当的堆栈大小的一些常用方法:
- 了解系统需求:首先需要了解程序的需求和特性。不同的应用程序可能具有不同的堆栈需求,取决于函数调用深度、局部变量的数量和大小等因素。
- 静态分析:对于已经编写的程序,可以通过静态分析工具或代码审查来估计堆栈使用情况。这涉及检查函数调用和递归深度、局部变量的大小以及递归调用终止条件等。
- 基于经验值:经验是确定堆栈大小的重要参考。对于特定的嵌入式平台和应用程序类型,可能存在一些通用的经验值。可以向嵌入式社区、厂商文档或其他开发者寻求建议。
- 测试和验证:在实际运行程序之前,可以进行堆栈大小的测试和验证。可以模拟程序的典型执行路径,并监测堆栈的使用情况。如果堆栈使用接近或超过堆栈大小限制,就需要增加堆栈大小。
- 迭代优化:堆栈大小的确定可能需要进行多次迭代和优化。在实际运行程序后,可以监测堆栈使用情况并根据需要进行调整,以平衡堆栈大小和系统资源的利用。
需要注意的是,堆栈大小的设置应该考虑到系统的内存限制和其他资源需求。过大的堆栈大小可能占用过多的内存,而过小的堆栈大小可能导致堆栈溢出错误。最佳的堆栈大小是根据具体的应用程序和嵌入式系统进行调整的,没有一种通用的方法适用于所有情况。因此,根据特定应用的需求和硬件平台的限制,确定适当的堆栈大小非常重要。
-
如何在编程中避免递归调用导致的堆栈溢出问题?
参考答案
要在编程中避免递归调用导致的堆栈溢出问题,可以采取以下方法:
迭代替代递归:将递归算法改写为迭代算法,使用循环结构代替递归函数的调用。迭代通常需要较少的堆栈空间,并且可以有效避免堆栈溢出问题。尾递归优化:如果递归函数的最后一个操作是递归调用,并且递归调用的返回值是当前函数的返回值,那么可以将递归优化为尾递归。尾递归优化可以使得递归函数在每次递归调用时重用相同的堆栈帧,从而避免堆栈溢出。限制递归深度:在递归函数中设置递归深度的上限,以避免无限递归导致堆栈溢出。这可以通过在递归函数中添加计数器或者使用条件判断来实现。使用动态内存分配:如果递归算法的堆栈深度无法预测,可以考虑使用动态内存分配来代替堆栈空间。通过使用堆上的内存,可以避免堆栈的限制。使用迭代器或生成器:对于一些需要遍历或处理递归数据结构的问题,可以考虑使用迭代器或生成器来实现。迭代器和生成器提供了一种迭代访问数据的方式,而不需要显式的递归调用,从而避免了堆栈溢出的问题。
-
解释中断和异常处理中堆栈的使用方式和注意事项。
参考答案
在计算机系统中,中断和异常处理是处理与正常程序执行流程不同的情况的机制。在这些情况下,系统需要保存当前正在执行的程序的上下文信息,以便在处理完中断或异常后能够恢复到正常执行流程。堆栈在中断和异常处理中起着重要的作用,用于保存和恢复程序的上下文信息。
当中断或异常发生时,处理器会自动保存当前正在执行的程序的上下文信息到堆栈中。这包括程序计数器(保存当前指令的地址)、寄存器状态和其他相关信息。然后,处理器会跳转到中断或异常处理程序,该程序会执行与中断或异常相关的操作。
在处理程序执行期间,堆栈用于保存处理程序的局部变量和临时数据。这些数据可以通过堆栈指针进行访问。当处理程序完成时,处理器从堆栈中恢复先前保存的上下文信息,包括程序计数器和寄存器状态,以便继续执行被中断或异常中断的程序。 使用堆栈进行中断和异常处理时,需要注意以下几点:
堆栈大小:为了确保堆栈能够容纳所有需要保存的上下文信息和处理程序的局部变量,堆栈的大小应该足够大。否则,可能会发生堆栈溢出的情况,导致数据丢失或系统崩溃。堆栈指针管理:堆栈指针是用于访问堆栈数据的重要指针。在中断和异常处理期间,必须正确地管理堆栈指针,确保保存和恢复上下文信息的正确性。中断和异常处理的嵌套:当系统出现多个中断或异常同时发生时,可能会发生处理程序的嵌套执行。在这种情况下,必须正确地保存和恢复多个处理程序的上下文信息,以避免数据丢失或处理错误。
-
在多线程环境中,如何管理和调试每个线程的堆栈?
参考答案
在多线程环境中,每个线程都有自己的堆栈,用于保存线程的局部变量和执行状态。下面是一些常用的方法和参考链接,可以帮助管理和调试每个线程的堆栈:
调试器:使用调试器是一种常见的方法,可以管理和调试每个线程的堆栈。调试器可以让你暂停线程的执行并检查其堆栈,查看局部变量、函数调用链和执行路径。常用的调试器包括GDB(GNU Debugger)和LLDB(LLVM Debugger)等。你可以通过调试器的命令和功能来管理和分析每个线程的堆栈。栈跟踪:栈跟踪是一种技术,用于获取当前线程的堆栈信息。通过在代码中插入栈跟踪代码或使用栈跟踪函数,可以获取每个线程的堆栈信息并输出到日志或终端。这样可以帮助你了解每个线程的执行路径和调用关系。具体的栈跟踪方法和函数库可能会依赖于所使用的编程语言和开发环境。性能分析工具:性能分析工具通常提供了监测和分析多线程应用程序的功能,包括堆栈分析。这些工具可以帮助你收集线程的执行信息和堆栈信息,并提供可视化界面来分析每个线程的堆栈情况。一些常用的性能分析工具包括perf、Intel VTune、Java VisualVM等。
参考资料:
-
解释嵌入式系统中的任务堆栈和中断堆栈的区别和用途。
参考答案
- 任务堆栈(Task Stack)是用于管理嵌入式系统中任务(或线程)执行的堆栈。每个任务都有自己的任务堆栈,用于保存任务的局部变量、函数调用信息和执行状态。任务堆栈的大小通常在任务创建时指定,并根据任务的需求进行调整。任务堆栈的主要作用是支持任务之间的切换和保存任务的执行上下文,以便能够在任务切换时恢复到上一个任务的执行状态。
- 中断堆栈(Interrupt Stack)是用于管理处理器中断和异常处理的堆栈。当中断或异常发生时,处理器会自动切换到中断堆栈,并保存当前执行的程序的上下文信息。中断堆栈用于保存中断或异常处理程序的局部变量、函数调用信息和执行状态。与任务堆栈不同,中断堆栈的大小通常是固定的,并且由硬件或操作系统预先定义。中断堆栈的目的是支持中断处理程序的执行,并确保在处理完中断或异常后能够返回到原来的程序执行位置。
区别: 3. 任务堆栈用于管理任务(或线程)的执行,而中断堆栈用于处理中断和异常。 4. 任务堆栈由操作系统或任务调度器进行管理,而中断堆栈由处理器和中断控制器进行管理。 5. 任务堆栈的大小可变,而中断堆栈的大小通常是固定的。
-
嵌入式系统中的堆栈与常规计算机系统中的堆栈有何不同?
参考答案
大小和固定性:嵌入式系统中的堆栈通常具有固定的大小,这是为了确保在资源受限的环境下有效地管理内存。这些固定大小的堆栈是在系统初始化时预先分配的,并且无法在运行时进行动态调整。而在常规计算机系统中,堆栈的大小通常是动态分配的,可以根据需要进行调整。分配方式:在嵌入式系统中,堆栈的分配通常是静态的。也就是说,每个任务或线程都会被分配一个固定大小的堆栈空间,这样可以确保每个任务都有足够的内存来保存局部变量和执行状态。而在常规计算机系统中,堆栈的分配是动态的,堆栈空间会随着函数调用的深度动态增长和收缩。上下文切换:嵌入式系统中的上下文切换通常是由操作系统或任务调度器进行管理。当一个任务被挂起,另一个任务开始执行时,任务的上下文信息(包括堆栈指针、寄存器状态等)会被保存和恢复。而在常规计算机系统中,上下文切换通常是由操作系统内核负责管理,包括保存和恢复堆栈、寄存器等信息。堆栈大小限制:由于嵌入式系统往往具有有限的资源,堆栈大小限制会更加严格。过大的堆栈可能导致内存消耗过多,而过小的堆栈可能导致堆栈溢出。因此,在嵌入式系统中需要仔细管理和配置堆栈大小,以适应系统的需求和资源限制。
-
什么是堆栈回溯(Stack Trace)?如何在嵌入式系统中实现堆栈回溯?
参考答案
堆栈回溯(Stack Trace)是一种技术,用于获取当前执行线程或进程的堆栈信息。它记录了函数调用链的顺序,包括每个函数的调用关系和返回地址。堆栈回溯可以提供有关程序执行路径和函数调用序列的详细信息,对于调试和错误排查非常有用。 在嵌入式系统中,实现堆栈回溯可能会受到一些限制,因为嵌入式系统 通常具有资源受限和实时性要求。以下是一些常见的方法用于在嵌入式系统中实现堆栈回溯:
编译器支持:某些嵌入式编译器可能提供了堆栈回溯的支持。通过在编译器选项中启用堆栈回溯功能,可以生成包含符号信息的可执行文件。这样,当发生错误时,可以使用特定的工具(如调试器)来提取堆栈回溯信息并分析问题。符号表和map文件:在编译嵌入式应用程序时,生成符号表和map文件是一种常见的做法。符号表中包含了函数名称、变量名称和其对应的地址等信息。map文件提供了程序代码和数据在内存中的分布信息。这些文件可以用于在运行时解析堆栈信息,从而获得堆栈回溯。手动堆栈跟踪:在特定的关键代码段或错误处理函数中,你可以手动记录堆栈信息。通过在代码中插入适当的跟踪函数或宏,可以获取堆栈的调用链和返回地址。这些信息可以记录到日志文件或其他存储介质中,以供后续分析和排查问题时使用。
-
什么是栈保护(Stack Guard)机制?如何防止栈溢出攻击?
参考答案
栈保护机制旨在检测和防止栈溢出攻击。它通过在堆栈上放置特定的保护值或使用其他技术来监测堆栈的完整性。当检测到栈被破坏或溢出时,栈保护机制会触发异常或中断,阻止恶意代码的执行。以下是一些常见的栈保护机制和防止栈溢出攻击的方法:
栈保护位(Stack Canary):栈保护位是一种常见的栈保护机制。在函数的栈帧中,将一个特殊的随机值(称为栈保护位或栈哨兵)放置在返回地址之前。函数执行完毕时,会检查栈保护位是否被修改。如果栈保护位的值被修改,说明栈溢出发生了,程序将终止执行。栈溢出检测技术:一些编程语言和编译器提供了栈溢出检测技术。例如,使用栈溢出检测函数(如canary函数)或编译选项(如-fstack-protector)可以在运行时检测栈溢出,并采取相应的防护措施。内存布局随机化(ASLR):ASLR 是一种安全机制,通过随机化程序的内存布局来增加攻击者的难度。通过随机化堆栈的地址,攻击者无法准确预测栈的位置和布局,从而降低栈溢出攻击的成功率。安全编程实践:编写安全的代码是防止栈溢出攻击的关键。使用安全的字符串处理函数,避免缓冲区溢出,限制用户输入的长度等都是重要的安全编程实践。
参考资料:
C语言编译相关知识
-
参考答案
C程序内存分配为以下五个区:
- text (或code): 存储可执行代码,通常是固定大小而且是只读的。
- data: 存储
已初始化的全局变量或静态局部变量。 - bss(Block Started by Symbol): 存储
未初始化的全局变量或静态局部变量。 - heap: 存储动态分配的内存段,一般从bss尾部往高地址内存区增长。
- stack: 用于调用栈,从高地址内存区往低地址内存区增长。
五个区的分布图可参考:

在上面的五个区中可以发现,
bss区和data区都是用于存储全局变量值或静态局部变量值的,只是前者是存储未初始化的,而后者是存储已初始化的。我们知道C语言中,未定义的static变量一般都会默认初始化为0,那么为什么还要拆成两个区来存储?其实之所以拆成
bss区和data区主要是为了减小程序大小。因为data区和bss区有如下的处理差异:- text 和 data 段都在可执行文件中,由系统从可执行文件中加载
- bss 段不在可执行文件中,由系统初始化。
即如果我们将无需初始化的变量放在bss区,bss区只存储标识符,那么只需要在程序启动时将需要初始化为0的未初始化变量初始化为0即可。这样可以减少程序大小,从而降低ROM空间的开销(在嵌入式设备上,采用更低规格的ROM可以降低成本)。
另外还需要注意的是,将程序划分为以上五个区只是典型的情况,不同的操作系统可能会有不同的实现。 参考资料:
-
gcc的编译有哪几个过程,每个过程的作用是什么?
参考答案
gcc编译分为四个过程:预处理、编译、汇编、链接。四个过程的作用分别如下:
- 预处理(c pre-processing):C Pre-processing简写为
cpp,在gcc编译过程中主要由cpp程序负责该过程的代码处理。该过程主要做一些文本的初始化处理(如移除注释)、源文件所需头文件(#include)内容拷贝到源文件中及将macro进行展开。预处理完后会生成*.i文件,是一下过程编译的的输入。在gcc上,可以使用如下命令对文件进行预处理:
gcc -E input.c -o input.i- 编译(Compilation): 编译过程将前一过程生成的
*.i文件进行编译以生成特定架构上的汇编代码。生成的汇编代码文件以s作为文件名后缀。在gcc上,可以使用如下命令生成文件的汇编代码:
gcc -S input.i- 汇编(Assembly):汇编过程将汇编代码转化为机器代码(即二进制文件),生成的文件以
o为文件名后缀。在gcc套件中,汇编过程是由as程序负责的,可以使用如下命令生成文件的机器代码:
gcc -c input.s- 链接(Linker): 链接过程将生成的二进制文件与依赖的库文件进行链接从而生成可执行文件。链接过程由程序
ld负责。
参考资料:
- 预处理(c pre-processing):C Pre-processing简写为
-
make的作用?
参考答案
make是软件开发过程中非常常用的一个工具,它读取工程中的
makefile文件以自动构建软件。makefile文件主要格式为:目标+依赖+规则,如下:target: dependencies <TAB>command-1 <TAB>command-2参考资料:
-
CMake的作用?
参考答案
CMake是一个跨平台的、开源的自动化建构系统,用于软件的自动构建、测试、打包和安装。CMake本身并不具备构建功能,而是通过读取
CMakeList.txt生成其它构建系统的构建文件(如生成make系统的makefile、生成Windows MSVC的projects/workspaces)。再通过这些生成的构建文件去做软件的构建。 对C/C++程序来说,CMake的优点主要有:- 支持跨平台,如Linux和Windows
- 脚本
较makefile简单易读
CMake的缺点也很明显:强大但也很复杂,调试麻烦,对开发人员要求较高。
参考资料:
-
解释编译器的前端、中端及后端的区别。
参考答案
编译器的编译过程分为前端(front-end)、中端(middle-end)和后端(back-end)。三个过程的作用分别如下:
- 前端:分析源码文件生成程序的中间表示(Intermediate representation, IR),该过程主要包括预处理、词法分析、语法分析和语义分析
- 中端:也被称为优化器,对前端生成的IR进行优化以提高程序的性能及质量
- 后端:主要处理CPU架构相关的优化及生成目标机器代码
参考资料:
-
什么是交叉编译?为什么在嵌入式开发中需要使用交叉编译器?
参考答案
交叉编译是在一个平台(主机平台)上生成另一个平台(目标平台)上的可执行代码。执行交叉编译的编译工具链即为交叉编译器。
在嵌入式开发中,通常需要使用交叉编译器的原因有以下几点:
同时支持不同的硬件平台:嵌入式设备通常基于特定的硬件平台,例如ARM、MIPS、PowerPC等。这些平台具有不同的指令集和体系结构。通过使用交叉编译器,可以在主机平台上编写和编译代码,然后将生成的目标代码移植到目标嵌入式设备上运行。主机与目标平台差异:主机平台通常是通用的计算机系统,例如PC或服务器,而目标平台是嵌入式设备。它们具有不同的操作系统、库和硬件资源。使用交叉编译器可以针对目标平台生成可执行代码,以便在目标设备上运行。开发效率:嵌入式设备通常具有有限的资源,通过使用交叉编译器,可以在开发环境中进行更快速的迭代和测试,而无需在实际的嵌入式设备上进行每一次更改的编译和部署。这加快了开发过程,并提供了更高的灵活性。
参考资料:
-
什么是链接器?它的作用是什么?
参考答案
链接器(
LinkerorLink editor)是一个将编译器生成的一个或多个目标文件(object files)链接为单一可执行程序、库文件或另一目标文件的程序。 链接器的主要作用有:符号解析(Symbol resolution):链接器负责解析目标文件中使用和定义的符号(函数、变量等)。当多个目标文件之间存在相互调用或引用的符号时,链接器会解析它们之间的关系,以确保符号在最终的可执行文件中能够正确地连接和使用。符号重定位(Symbol relocation):目标文件中的符号通常是相对于其所在模块的位置进行编码的。链接器负责将这些相对地址转换为绝对地址,以便在最终的可执行文件中正确定位符号的位置。合并和组织代码(Code merging and organization):链接器将多个目标文件中的代码段和数据段合并成一个单一的可执行文件。它负责处理代码段的重定位和修复,以确保各个模块之间的跳转和引用是正确的。解决库依赖(Library dependency resolution):链接器能够解决可执行文件或共享库对外部库的依赖关系。当一个目标文件引用了外部库中的函数或变量时,链接器会定位并将相关的库文件与可执行文件进行关联,以确保在运行时可以正确地调用和使用库中的功能。符号表生成(Symbol table generation):链接器还会生成一个符号表,其中包含所有目标文件中定义和引用的符号信息。这个符号表在调试和符号查找时非常有用。
参考资料:
-
解释静态链接和动态链接的区别
参考答案(答案来源于ChatGpt)
静态链接(Static Linking)和动态链接(Dynamic Linking)是在编译和链接过程中使用的两种不同的方法。
静态链接是指在编译和链接时,将目标文件和库文件的代码和数据合并到最终的可执行文件中。在静态链接的情况下,目标文件中使用的所有库函数和库文件的代码都被复制到最终的可执行文件中。这意味着可执行文件独立于系统上的任何库文件,它包含了所有运行所需的代码和数据。在运行时,可执行文件不需要额外的依赖,可以直接执行。
动态链接是指在编译和链接时,目标文件只包含对库函数的引用,而不包含实际的库函数代码和数据。在运行时,操作系统会动态加载所需的库文件,并将其与可执行文件进行链接。这意味着可执行文件本身较小,只包含了对库函数的引用,而实际的库函数代码和数据在运行时从共享库(shared library)中加载。多个可执行文件可以共享同一个共享库,从而节省了存储空间。
区别如下:
-
大小:静态链接生成的可执行文件通常比较大,因为它包含了所有所需的代码和数据。而动态链接生成的可执行文件相对较小,因为它只包含对库函数的引用。 -
可维护性:静态链接生成的可执行文件是独立的,不依赖于外部库文件。这样可以确保程序在不同环境中的运行一致性。但是,如果库文件有更新或修复,需要重新编译和链接可执行文件。而动态链接使得库文件可以独立于可执行文件进行更新和维护,只需要更新库文件而不需要重新编译和链接可执行文件。 -
内存使用:静态链接时,每个可执行文件都会包含所需的库函数代码和数据,可能导致内存占用增加。而动态链接时,多个可执行文件可以共享同一个库的实例,节省了内存占用。 -
运行时依赖:静态链接生成的可执行文件在运行时不需要外部库文件的存在,可以直接运行。而动态链接生成的可执行文件在运行时需要依赖库文件,如果库文件不存在或版本不兼容,程序将无法执行。
总结:静态链接将所有的代码和数据合并到可执行文件中,使其独立运行;动态链接在运行时加载所需的库文件,使得可执行文件更小,并且可以共享库文件,提高了可维护性和内存使用效率。
参考资料:
-
-
什么是库文件(Library)?解释静态库和动态库在嵌入式开发中的使用场景。
参考答案(答案来源于ChatGpt)
库文件(Library)是一组预编译的代码和数据,提供了特定功能的函数,以供其他程序在编译和链接过程中使用。库文件可以包含可重用的代码、函数、变量和其他资源,它们被设计成可供多个程序共享和重复使用。
在嵌入式系统中,通常会使用静态库来最大限度地减少系统资源的占用,尤其是对于具有严格的资源限制的系统。动态库可能在嵌入式系统中使用较少,但在一些特定场景下仍然有用,例如共享某些通用功能的库文件,以便多个应用程序可以共享和更新这些功能。
-
请讨论一些常见的编译器选项和优化策略,以优化嵌入式软件的性能和大小。
参考答案(答案来源于ChatGpt)
常用的优化软件性能和大小的编译器选项有:
-Os:此选项将编译器优化为最小化代码大小。它会执行一系列优化,包括消除未使用的代码、常量折叠和传播、简化表达式等。-O2或-O3:这些选项表示编译器使用更高级别的优化来提高性能和代码大小。较高级别的优化可能会增加编译时间,但通常会提供更好的性能。-ffunction-sections -fdata-sections:这些选项将代码和数据分离成小节,以便进行进一步的优化和链接时的死代码消除。这可以减小最终的可执行文件大小。-flto:此选项启用链接时优化(Link Time Optimization),它在链接过程中对整个程序进行优化。这可以提供更高级别的优化和更好的性能。-finline-functions:此选项启用函数内联优化,将函数调用替换为函数体的副本。这减少了函数调用的开销,提高了性能。-fomit-frame-pointer:此选项告诉编译器省略函数调用时的Frame Pointer,从而减少了堆栈操作和代码大小。-march和-mtune:这些选项用于指定目标处理器的体系结构和微体系结构,以便编译器能够生成针对特定处理器优化的代码。-falign-functions和-falign-loops:这些选项控制函数和循环的对齐方式,以提高内存访问的效率。-fno-unroll-loops:此选项禁用循环展开优化,适用于循环次数较多或代码大小有限的情况。
参考资料:
-
解释编译器标志(Compiler Flag)-nostdlib的作用,并讨论在嵌入式开发中使用它的情景。
参考答案(答案来源于ChatGpt)
编译器标志(Compiler Flag)
-nostdlib用于告诉编译器不要使用默认的标准库(standard library)。默认情况下,编译器会链接标准库以提供一些常见的函数和功能,如输入/输出、内存分配等。然而,在某些嵌入式开发场景中,可能需要更加精简的运行时环境,不需要使用完整的标准库。这时可以使用
-nostdlib标志来排除默认的标准库。使用
-nostdlib标志的情景包括:-
嵌入式系统的资源限制:在一些嵌入式系统中,资源有限,包括处理器性能、存储空间和内存。使用-nostdlib标志可以避免链接大型标准库,减小可执行文件的大小,节省存储空间。 -
替代标准库:在某些嵌入式系统中,可能有自定义的库或者第三方的轻量级库,可以替代标准库的部分功能。通过使用-nostdlib标志,可以链接这些特定的库而不链接默认的标准库。 -
裸机编程:在裸机编程中,可能直接访问硬件寄存器和设备,而不需要标准库提供的抽象层。使用-nostdlib标志可以避免链接标准库,确保代码直接操作硬件。
使用
-nostdlib标志后,需要手动处理输入/输出、内存分配等功能的实现,或者使用其他替代方案。此外,可能还需要指定其他必要的链接选项和库文件,以满足特定嵌入式系统的需求。参考资料:
-
-
什么是目标文件和可执行文件?它们的区别是什么?
参考答案(答案来源于ChatGpt)
- 目标文件(Object File)是编译器在编译源代码后生成的中间文件,它包含了已编译代码的二进制表示形式、符号表和其他调试信息,但尚未进行最终的链接操作。
- 可执行文件(Executable File)是经过链接器将一个或多个目标文件以及所需的库文件合并后生成的最终可执行程序。可执行文件包含了完整的机器指令、数据和其他所需的资源,可以直接在操作系统上运行。
其区别如下:
- 目标文件是编译的中间产物,包含了已编译代码的二进制表示形式和符号表,但它们还没有被链接起来形成可执行程序。
- 可执行文件是最终生成的可执行程序,它包含了所有链接的目标文件和库文件,具有完整的机器指令、数据和其他资源,可以直接运行
参考资料:
-
解释链接时的符号解析过程是什么?包括全局符号和局部符号的解析。
参考答案(答案来源于ChatGpt)
链接时的符号解析过程是链接器在将多个目标文件或库文件合并成可执行文件或目标文件时,解决符号引用(Symbol Reference)的过程。符号解析涉及全局符号和局部符号的解析。
-
全局符号解析:
- 全局符号是在多个源文件中定义和使用的全局变量、函数和对象。它们可以在不同的源文件中定义,但在链接过程中需要确保它们的引用是正确解析的。
- 链接器首先会收集所有目标文件中的全局符号,并将其保存到一个符号表中。符号表记录了全局符号的名称、类型和定义位置等信息。
- 在解析引用时,链接器会遍历所有引用的全局符号,并在符号表中查找对应的定义。如果找到了匹配的定义,链接器将将引用的地址绑定到正确的定义位置上。
-
局部符号解析:
- 局部符号是在单个源文件中定义和使用的局部变量、函数和对象。它们的作用域限定在源文件内部,对于其他源文件是不可见的。
- 局部符号的解析是在单个目标文件的编译过程中进行的。编译器会为每个局部符号分配唯一的标识符或地址,并在编译过程中将符号引用绑定到相应的符号定义。
- 在链接过程中,局部符号的解析是通过地址绑定实现的。编译器为每个局部符号分配了唯一的地址,链接器通过地址绑定将引用的地址绑定到正确的定义位置上。
-
-
什么是位置无关代码(Position-Independent Code,PIC)?它在嵌入式系统中的作用是什么?
参考答案(答案来源于ChatGpt)
位置无关代码(Position-Independent Code,PIC)是一种编译和链接的方式,使得代码在内存中的位置可以灵活地确定,而不依赖于固定的绝对地址。PIC的主要目的是实现可移植性和共享代码的能力。
在嵌入式系统中,PIC有以下几个作用:
内存布局灵活:嵌入式系统通常有限的内存资源,而且内存布局可能因为硬件限制或操作系统要求而发生变化。使用PIC可以使得代码可以加载到任意的内存地址,并且代码内部的引用和跳转也是相对的,因此不依赖于固定的绝对地址。共享库和动态链接:嵌入式系统中,共享库(或动态链接库)的使用是常见的,可以节省存储空间并提高代码的复用性。PIC使得共享库可以加载到任意的内存地址,并且可以同时被多个程序共享。代码保护和安全性:使用PIC可以增强代码的安全性,防止针对特定地址的攻击。由于代码不依赖于固定的绝对地址,恶意用户很难通过攻击特定地址来破坏系统。
总而言之,位置无关代码在嵌入式系统中的作用是实现代码的灵活加载和共享,适应有限的内存资源和可移植性要求,并增强代码的安全性。
参考资料:
gdb使用相关知识
-
什么是
gdb? -
gdb常见命令有哪些?
参考答案
gdb的常见命令有:
- help: 获取gdb命令帮助
- help
<command>: 获取特定gdb命令的帮助 - run: 运行到下个断点或程序结束
- step: 单步(逐语句)调试,会进入到函数内部执行
- next: 单步(逐语句)调试,但不会进入到函数内部执行
- finish: 结束当前函数或循环
- continue: 执行到下个断点或程序结束
- up
<N>: 往栈顶移动N帧,N默认为1 - down
<N>: 往栈顶移动N帧,N默认为1 - list: 打印当前点附近的代码
- print
<name>: 打印名为name的变量值 - print *
<name>: 打印name指针指向的值 - print/x
<name>: 以16进制打印name的值 - print
<name>@<n>: 打印以name为起始地址的n个值 - break
<name>: 在函数name处设置断点 - break
<num>: 在行num处设置断点 - disable 1: 去使能断点1
- enable 1: 使能断点1
- delete 1: 删除断点1
- delete: 删除所有断点
- condition 1
<expr>: 断点1的停止条件为表达式expr为true - condition 1: 删除断点1的所有条件
- info break: 显示所有的断点信息
- backtrace: 查看栈信息
- display
<name>: 始终显示变量name的值 - undisplay
<name>: 取消跟踪name的值 - watch
<expr>: 监视expr的值,一旦有变化就暂停程序
参考资料:
-
gdb调试的原理是?
参考答案
gdb使用系统调用ptrace(process trace)去观察和控制其它进程的执行、检查和修改其它进程的内存和寄存器。ptrace的原型如下:long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data);根据
ptrace的manual手册,主要有两种跟踪进程的方式:-
父进程通过
fork系统调用创建子进程,在子进程中作如下ptrace调用,然后再通过execv加载子进程程序。ptrace(PTRACE_TRACEME, 0, 0, 0); -
使用如下
ptrace调用直接跟踪其它进程:ptrace(PTRACE_ATTACH, pid, 0, 0);
当进程被跟踪时,每当有信号(signal)被分发给被跟踪的进程(tracee)时都会导致tracee暂停(
SIGKILL是个例外)。进行跟踪的进程(tracer)通过waitpid系统调用(或类似的wait相关的系统调用)获知tracee被跟踪的情况。当tracee停止时,tracer还可以使用多种ptrace request去检查或修改tracee。gdb断点(breakpoint)功能的软件实现原理是在指定位置插入断点指令(INT),当被调试的程序执行到断点位置时,产生
SIGTRAP信号并转由gdb处理。参考资料:
-
-
如何调试
多进程程序?参考答案
当我们使用
gdb调试多进程程序时,如果进程使用fork创建了子进程,gdb仍会继续跟踪原来的进程,子进程正常执行。要想允许调试子进程,有两种方法:- 使用
attch pid的方式跟踪子进程,其中pid为子进程的进程ID - 在
gdb中使用set follow-fork-mode配置fork时跟踪子进程还是父进程
参考资料:
- 使用
-
如何调试
多线程程序?参考答案
gdb提供以下功能调试多线程程序:- 新线程创建的自动提醒
thread <threadno>命令用于在调试的进程间切换info threads命令用于查询所有已存在的线程thread apply <threadno> <all> args命令用于对指定的一条线程或多条指令应用指令- 用于线程的断点
需要注意的是,
threadno是gdb为每个线程分配的线程ID,是一个内部ID参考资料:
-
什么是
core文件?有什么作用?参考答案
core文件指core dump file,是操作系统在进程收到某些信号而终止时,将此时进程空间的内容及有关进程的状态的其它信息写入一个磁盘文件。core文件中的信息一般用于调试。 程序自身的core dump file一般可以用于分析程序是在哪里错了,而外部程序触发的core dump file一般来于分析进程的运行情况,比如分析内存使用、线程状态等。core dump的缺点有:- 性能问题:对进程进行core dump可能会耗费大量系统资源、造成内存清理的延迟,尤其是占用大量内存的进程。
- 磁盘空间问题:对进程进行core dump会占用大量磁盘空间。
- 安全问题:core文件可能包含敏感数据(如密码和密钥),这部分敏感数会被写入到磁盘。
Linux上要去使能core dump功能,有以下方式:
- 使用
sysctl设置kernel.core_pattern的值为/dev/null - 按如下方式配置
/etc/systemd/coredump.conf.d/custom.conf:
``` [Coredump] Storage=none ```- 按如下方式配置
/etc/security/limits.conf:
``` * hard core 0 ```- 使用
ulimit指令:ulimit -c 0
使用
gdb对已有进程生成core dump file的方式为:gdb -p <pid>启动对进程的调试,其中<pid>为进程的进程ID- 在
gdb中使用指令generate-core-file生成core dump file
参考资料:
-
如何使用GDB进行远程调试?
参考答案
使用GDB进行远程调试通常需要以下步骤:
- 准备目标设备和调试主机:
- 确保目标设备和调试主机在同一网络中,并可以相互通信。
- 在目标设备上安装并运行GDB服务器软件,例如OpenOCD、J-Link GDB Server等。
- 在调试主机上安装GDB调试器。
- 启动GDB服务器:
- 在目标设备上运行GDB服务器,配置它以监听特定的端口,例如TCP端口。
- 连接到目标设备:
- 在调试主机上打开终端或命令行界面,启动GDB调试器。
- 使用GDB的"target remote"命令连接到目标设备的IP地址和端口,例如:
target remote <target_ip_address>:<port>。
- 加载和调试程序:
- 使用GDB的"file"命令加载目标设备上的可执行文件,例如:
file <executable_file>。 - 设置断点、单步执行或其他调试操作,以控制程序的执行。
- 使用GDB的其他命令进行调试,例如查看变量、回溯函数调用等。
- 使用GDB的"file"命令加载目标设备上的可执行文件,例如:
需要注意的是,远程调试的具体步骤可能因目标设备和调试工具的不同而有所差异。建议参考相关的GDB调试器和GDB服务器的文档,以了解更详细的配置和使用说明。
参考资料:
- 准备目标设备和调试主机:
计算机网络基础知识
-
OSI七层模型是怎样的?每层的作用是什么?
参考答案
OSI七层模型是
ISO组织提出的,试图使各种计算机在世界范围内互连为网络的标准框架。OSI模型并没有提供实现的方法,仅提供一个概念框架,共分为七层,从低到上分别为:物理层(Physical Layer): 负责在不同的物理设备之间传递和接收比特流,该层会将数字信号转移为电信号或光信号等。支持的协议包含Ethernet、WiFi等数据链路层(Data link Layer): 在由物理层连接的两个节点间传输数据帧(Data Frames),实现可靠的数据传输。支持的协议包含Ethernet、WiFi、PPP等网络层(Network Layer): 处理数据包在网络中的路由和转发。支持的协议包含IP、ICMP、ARP等传输层(Transport layer): 提供可靠的端到端数据传输。支持的协议包含TCP、UDP等会话层(Session Layer): 建立、管理和终止会话。支持的协议包含RPC等表示层(Presentation Layer): 实现数据格式的转换、加密和压缩。支持的协议包含SSL等应用层(Application Layer): 提供应用程序之间的通信。支持的协议包含SSH、HTTP等
参考资料:
-
TCP/IP四层模型是怎样的?每层的作用是什么?
参考答案(答案来源于ChatGpt)
TCP/IP模型是一个常用的网络协议栈,它包含四个层次,每个层次都有特定的功能和作用。以下是TCP/IP模型的各层次及其作用:
网络接口层(Network Interface Layer):- 作用:提供物理网络和数据链路层之间的接口,处理数据帧的发送和接收,以及物理地址(MAC地址)的解析和处理。
- 协议:Ethernet、Wi-Fi、PPP(点对点协议)等。
网络层(Internet Layer):- 作用:处理数据包的路由和转发,实现不同网络之间的数据通信,以及网络寻址和逻辑地址(IP地址)的管理。
- 协议:IP(Internet Protocol)、ICMP(Internet Control Message Protocol)、ARP(Address Resolution Protocol)等。
传输层(Transport Layer):- 作用:提供端到端的可靠数据传输服务,确保数据的可靠性和完整性,并处理多个应用程序之间的数据传输。
- 协议:TCP(Transmission Control Protocol)、UDP(User Datagram Protocol)等。
应用层(Application Layer):- 作用:支持特定的网络应用程序,提供各种应用层协议和服务,使应用程序能够进行数据交换和通信。
- 协议:HTTP(Hypertext Transfer Protocol)、FTP(File Transfer Protocol)、SMTP(Simple Mail Transfer Protocol)、DNS(Domain Name System)等。
需要注意的是,TCP/IP模型中的层次与OSI七层模型不完全对应。网络接口层对应了OSI模型的物理层和数据链路层,而网络层在一定程度上涵盖了OSI模型的网络层功能,传输层和应用层则在OSI模型的传输层和应用层上进行了合并和扩展。
TCP/IP模型是互联网的基础协议栈,它定义了一组协议和规范,使得不同计算机和网络设备能够进行互联并进行数据通信
http协议相关知识
-
http和https有什么区别?
参考答案(答案来源于ChatGpt)
HTTP(Hypertext Transfer Protocol)和HTTPS(Hypertext Transfer Protocol Secure)是用于在客户端和服务器之间传输数据的两种协议。它们的主要区别在于安全性和加密方面:
-
安全性:HTTP是一种不安全的协议,数据在传输过程中以明文形式传输,容易被攻击者窃听、篡改或伪装。而HTTPS通过使用TLS(Transport Layer Security)或SSL(Secure Sockets Layer)协议对数据进行加密和认证,提供了更高的安全性和保密性。 -
加密通信:HTTP不提供数据的加密传输,使得敏感信息(如登录凭据、信用卡号等)容易被攻击者获取。而HTTPS使用SSL/TLS协议对通信进行加密,确保数据在传输过程中的机密性,使得攻击者无法轻易获取敏感信息。 -
证书验证:HTTPS使用SSL/TLS证书对服务器进行身份验证,确保客户端与服务器之间的通信建立在可信任的连接上。客户端会验证服务器的证书,以确保与合法和受信任的服务器建立连接。这样可以防止中间人攻击和DNS劫持等安全威胁。 -
默认端口:HTTP使用端口号80进行通信,而HTTPS使用端口号443进行加密通信。
HTTPS在保护用户隐私和数据安全方面比HTTP更加可靠,因此在需要保护敏感信息的场景,如电子商务网站、在线支付平台等,推荐使用HTTPS。
参考资料:
-
TCP && UDP基础知识
-
tcp和udp有什么区别?一般用于哪些场景?
参考答案(答案来源于ChatGpt)
TCP(Transmission Control Protocol)和UDP(User Datagram Protocol)是两种常见的传输层协议,它们有以下区别:
-
可靠性:TCP提供可靠的数据传输,确保数据的完整性和顺序性。它使用确认机制、重传机制和流量控制来处理丢失、重复、损坏和失序的数据。而UDP是无连接的、不可靠的协议,它不提供数据的可靠性保证,数据包可能会丢失或以乱序的方式到达。 -
速度和效率:由于TCP提供可靠性保证,它的传输速度较慢。TCP维护连接状态信息、进行确认和重传,这些额外的开销会带来一定的延迟和网络开销。相比之下,UDP没有这些额外的开销,传输速度更快,延迟更低。 -
连接性:TCP是面向连接的协议,通信双方在传输数据之前需要先建立连接,然后进行数据传输,最后再关闭连接。UDP是无连接的协议,发送方可以直接发送数据包给接收方,无需建立连接。 -
数据包大小:TCP没有数据包大小限制,可以传输较大的数据。UDP的数据包大小受限制,每个数据包的最大长度为64KB,如果超过这个限制,数据将被分片或被丢弃。 -
适用场景:TCP适用于对数据完整性和顺序性要求较高的场景,如网页浏览、文件传输、电子邮件等。UDP适用于实时性要求高、数据丢失不重要的场景,如实时音视频传输、在线游戏、DNS查询等。
总的来说,TCP提供可靠的、有序的数据传输,适用于对数据完整性要求高的场景。而UDP提供快速的、无连接的数据传输,适用于实时性要求高、对数据可靠性要求较低的场景。
需要根据具体应用需求和场景来选择使用TCP还是UDP。有些应用可能同时使用两种协议,如视频会议应用可以使用UDP传输实时音视频数据,同时使用TCP传输控制和数据确认信息。
参考资料:
-
操作系统基础知识
-
解释嵌入式系统是什么?它与常规计算机系统有何不同?
参考答案
嵌入式系统是一种专门设计用于执行特定任务的计算机系统。与常规计算机系统(如个人计算机)相比,嵌入式系统通常具有以下特点:
特定功能:嵌入式系统是为特定的任务或应用程序而设计的,例如工业自动化、医疗设备、汽车控制系统等。它们被用于执行特定的功能,通常具有固定的硬件和软件配置。严格的资源限制:由于嵌入式系统通常具有较小的尺寸、较低的功耗和较有限的资源(如内存和处理能力),因此设计嵌入式系统时需要特别注意资源的优化和利用。实时性要求:许多嵌入式系统需要实时响应,即需要在严格的时间限制内对事件做出快速反应。这些系统通常使用实时操作系统(RTOS)来确保任务的及时执行。硬件和软件紧密集成:嵌入式系统中的硬件和软件通常紧密集成,以实现高效的功能。嵌入式系统可能包括专用的处理器、传感器、执行器和其他外围设备。可靠性和稳定性:许多嵌入式系统用于关键任务和长时间运行,因此对可靠性和稳定性有很高的要求。它们需要能够在各种环境条件下稳定运行,并保证数据的完整性和系统的可靠性。
参考资料:
-
解释实时操作系统(RTOS)及其在嵌入式系统中的作用。
参考答案
实时操作系统(RTOS)是一种专门设计用于实时应用程序的操作系统。实时应用程序需要在特定的时间约束内对事件作出快速响应,因此RTOS旨在提供可靠、可预测的系统响应性能。 RTOS在嵌入式系统中起着重要作用,因为嵌入式系统通常用于控制、监测和操作各种设备和系统。以下是RTOS在嵌入式系统中的几个关键作用:
时间管理:RTOS通过提供任务调度和事件管理功能,确保系统中的任务按照优先级和时间要求进行合理调度。它可以分配和管理任务的处理时间,确保关键任务能够按时完成,从而满足实时性要求。中断处理:嵌入式系统通常依赖于硬件中断来处理外部事件。RTOS能够有效管理中断请求,及时响应和处理来自外部设备的中断,并且可以根据优先级来处理多个中断请求。任务管理:RTOS允许将系统功能划分为多个独立的任务,每个任务都有自己的优先级和执行时间要求。RTOS负责调度和管理这些任务,确保它们以正确的顺序和时间执行,从而实现系统的并发和实时性。资源管理:嵌入式系统中的资源(如处理器、内存、输入/输出等)通常是有限的。RTOS提供资源管理功能,确保不同任务之间对共享资源的访问进行合理分配和调度,以防止冲突和资源争用。通信和同步:RTOS提供了各种通信机制和同步原语,用于任务之间的信息交换和协调。这些机制可以包括消息队列、信号量、事件标志等,用于实现任务之间的通信和同步操作。可靠性和容错性:RTOS通常设计为高可靠性和容错性,以应对嵌入式系统中的错误和异常情况。它提供了错误处理机制、任务监控和故障恢复等功能,以确保系统能够在异常情况下正确运行并保持稳定性。
-
请解释嵌入式系统的时钟和定时器,并说明它们在系统中的作用。
参考答案
- 时钟:嵌入式系统的时钟是一个基础设施,它提供了系统的时间参考。时钟可以是硬件上的晶振或其他类型的振荡器,用于生成系统的时钟信号。这个时钟信号驱动处理器、外设和其他系统组件的操作,用于同步它们的工作。时钟还用于测量时间间隔和执行时间相关的操作。
- 定时器:嵌入式系统的定时器是一个计数器,它在特定时间间隔内产生中断或触发事件。定时器可以设置为按固定时间间隔触发中断,也可以根据需要进行编程以满足系统需求。定时器通常具有预分频器和计数器,用于精确地控制定时器的周期和精度。
-
什么是并行处理和并发处理?在嵌入式系统中有何区别和应用场景?
参考答案
-
并行处理(Parallel computing):并行处理是指同时执行多个任务或操作,利用多个处理单元(如多个处理器核心)并行地完成任务。在并行处理中,多个任务可以同时进行,每个任务由不同的处理单元处理,从而加快整体系统的处理速度。并行处理通常需要专门的硬件支持,如多核处理器或并行计算机系统。 -
并发处理(Concurrency):并发处理是指同时处理多个任务或操作,通过时间片轮转或其他调度算法,使得多个任务交替执行。在并发处理中,每个任务在时间上交替执行,虽然不能同时进行,但通过快速切换和调度,给用户一种同时执行的感觉。
区别:
-
并行处理:在嵌入式系统中,并行处理常用于需要高性能和高吞吐量的应用场景,例如图像和视频处理、信号处理和实时控制系统等。通过利用多个处理核心同时执行不同的任务,可以提高系统的实时性和响应能力。 -
并发处理:在嵌入式系统中,由于资源有限或任务优先级不同,常常需要采用并发处理的方式。例如,实时操作系统(RTOS)使用任务调度器来管理和调度多个任务,每个任务按照一定的时间片轮转方式执行。这样可以实现多个任务的同时进行,提高系统的资源利用率和任务的响应速度。
参考资料:
-
-
请解释I2C和SPI总线协议,并说明它们在嵌入式系统中的应用。
参考答案
I2C(Inter-Integrated Circuit)和SPI(Serial Peripheral Interface)是两种常用的串行通信总线协议,在嵌入式系统中具有不同的特点和应用。
- I2C总线协议:I2C是一种双线制的串行通信协议,由两根线组成:串行数据线(SDA)和串行时钟线(SCL)。它支持多主设备和多从设备的通信,并且可以在设备之间共享同一条总线。I2C使用主从架构,主设备负责发起通信和控制总线访问,而从设备则被动响应。
在嵌入式系统中,I2C广泛应用于连接各种外设和传感器,例如温度传感器、加速度计、EEPROM、LCD显示屏等。
I2C通信简单且灵活,适用于连接多个设备并节省引脚数量的场景。 - SPI总线协议:SPI是一种四线制的串行通信协议,由四根线组成:主设备输出(MOSI)、主设备输入(MISO)、时钟线(SCK)和片选线(SS)。SPI通信中,有一个主设备控制通信,可以连接多个从设备,并且每个从设备都有一个片选线用于选择通信的目标设备。
在嵌入式系统中,SPI常用于高速数据传输和与外部设备的通信。它适用于连接各种外设,如闪存存储器、数据转换器、传感器、显示屏、无线模块等。
SPI通信速度快,适合于需要高带宽和实时性的应用场景。
参考资料:
- I2C总线协议:I2C是一种双线制的串行通信协议,由两根线组成:串行数据线(SDA)和串行时钟线(SCL)。它支持多主设备和多从设备的通信,并且可以在设备之间共享同一条总线。I2C使用主从架构,主设备负责发起通信和控制总线访问,而从设备则被动响应。
在嵌入式系统中,I2C广泛应用于连接各种外设和传感器,例如温度传感器、加速度计、EEPROM、LCD显示屏等。
-
什么是嵌入式固件?
参考答案
- 嵌入式固件(Firmware)是指嵌入在嵌入式系统中的软件程序或代码,用于控制和管理硬件设备的操作。它是一种针对特定硬件平台和应用需求编写的低级软件,通常以二进制形式存储在非易失性存储器(如闪存或EEPROM)中。
- 嵌入式固件在嵌入式系统中扮演着关键的角色,它负责控制硬件设备的功能和行为,实现系统的特定功能。嵌入式固件通常包括引导程序(bootloader)、驱动程序、实时操作系统(RTOS)、应用程序等,它们共同协同工作以实现嵌入式系统的预期功能。
- 嵌入式固件通常具有以下特点:
- 专用性:嵌入式固件是为特定的硬件平台和应用需求而设计,具有特定的功能和功能限制。
- 实时性:很多嵌入式系统需要实时响应和精确的控制,嵌入式固件需要满足实时性要求。
- 资源受限:嵌入式系统通常具有有限的处理能力、存储空间和能源,嵌入式固件需要高效地利用这些资源。
- 可靠性:嵌入式固件需要稳定可靠,能够长期运行且抵抗外部干扰和故障。
参考资料:
-
解释嵌入式系统中的电源管理,包括低功耗模式和睡眠模式等。
参考答案
在嵌入式系统中,电源管理是一种关键的技术,用于管理和控制系统的能源消耗,以提高系统的效率和延长电池寿命。其中,低功耗模式和睡眠模式是常见的电源管理技术。
低功耗模式(Low Power Mode): 低功耗模式是指嵌入式系统在空闲或非活动状态下切换到低功耗状态,以降低功耗并节省能源。在低功耗模式下,系统关闭或减少不必要的功能模块和外设的工作,降低时钟频率和电压,以及降低处理器的功耗等。系统在需要时可以快速恢复到正常工作状态。睡眠模式(Sleep Mode): 睡眠模式是一种更低功耗的模式,用于将嵌入式系统完全或部分关闭,以最大限度地减少功耗和能源消耗。在睡眠模式下,系统关闭主要的时钟和电源,只保留必要的电路运行。通常需要外部触发或定时器来唤醒系统,从而恢复正常运行状态。
-
什么是嵌入式系统中的调试和测试方法?请提及您熟悉的调试和测试工具。
参考答案
以下是一些常见的嵌入式系统调试和测试方法及工具:
- 调试方法:
- 打印输出:在代码中插入调试打印语句,将变量值、状态信息等输出到终端或日志文件中,以便分析程序的执行流程和数据状态。
- 断点调试:使用集成开发环境(IDE)提供的调试器,在关键代码位置设置断点,以暂停程序执行并检查变量、观察内存状态等。
- 运行时跟踪:通过记录代码执行路径和函数调用顺序等信息,进行运行时分析和跟踪,以了解系统的行为和性能瓶颈。
- 仿真和模拟:使用仿真器或模拟器在主机上运行嵌入式系统,以模拟硬件环境并进行调试。
- 测试方法:
- 单元测试:对嵌入式系统中的各个模块进行独立的测试,验证其功能的正确性和边界条件的处理。
- 集成测试:将多个模块或组件组合在一起进行测试,确保它们能够正确地协同工作。
- 硬件/软件集成测试:验证嵌入式系统的硬件和软件之间的接口和交互,确保它们能够正确配合运行。
- 验收测试:在目标环境中对整个嵌入式系统进行全面的测试,验证其符合用户需求和规格要求。
- 调试和测试工具:
- 调试器(Debugger):如GDB、JTAG调试器等,用于设置断点、监视变量和寄存器等,以及跟踪程序执行。
- 逻辑分析仪(Logic Analyzer):用于捕获和分析嵌入式系统中的数字信号,以了解信号的时序和状态。
- 示波器(Oscilloscope):用于观察和分析嵌入式系统中的模拟信号波形,以诊断和验证电路的正确性。
- 静态分析工具(Static Analysis Tools):如Lint、Coverity等,用于静态代码分析,发现潜在的错误和缺陷。
- 单元测试框架:如Unity、CppUTest等,用于编写和执行单元测试,并生成测试报告和覆盖率分析。
- 调试方法:
-
如何优化嵌入式系统的性能和功耗消耗?
参考答案
要优化嵌入式系统的性能和功耗消耗,可以采取以下几种方法:
- 优化算法和数据结构:通过优化代码中的算法和数据结构,减少系统的计算和存储需求,从而提高性能并减少功耗。使用更高效的算法和数据结构可以减少处理器的工作量和内存访问次数,从而节省能量。
- 优化代码实现:编写高效的代码可以减少系统的执行时间和功耗消耗。使用合适的编程技术和优化方法,如循环展开、内联函数、去除空闲代码等,可以提高代码的执行效率和功耗效率。
- 硬件优化:对硬件进行优化可以提高系统的性能和功耗效率。例如,选择适当的处理器和外设,设计合理的电路布局,采用低功耗组件和电源管理技术,以降低功耗消耗。
- 电源管理:合理的电源管理可以有效降低系统的功耗。通过使用节能模式、睡眠模式和动态电压频率调节(DVFS)等技术,根据系统负载和需求动态调整处理器的频率和电压,以实现功耗优化。
- 任务调度和优先级管理:使用合适的任务调度算法和优先级管理策略,确保关键任务得到及时执行,非关键任务进入低功耗状态。通过合理的任务调度和功耗管理,可以提高系统的性能和功耗效率。
- 性能分析和优化工具:使用性能分析工具和优化工具,如编译器的优化选项、性能分析器和能耗分析器,来评估系统的性能和功耗状况,并根据结果进行针对性的优化。
- 系统级优化:考虑整个系统的架构和设计,在硬件和软件层面进行综合优化。通过合理的模块划分、通信协议的优化、缓存管理和存储器优化等手段,提高系统的整体性能和功耗效率。
优化嵌入式系统的性能和功耗消耗是一个综合考虑多个因素的过程,具体的优化方法和技术取决于具体的嵌入式系统和应用场景。
-
什么是硬实时系统和软实时系统?举例说明两者之间的区别。
参考答案
硬实时系统和软实时系统是嵌入式系统中常用的两种实时系统类型,它们在任务处理和满足实时要求方面有一些区别。
-
硬实时系统(Hard Real-Time System):硬实时系统对任务的响应时间有严格的要求,必须在规定的时间限制内完成。在硬实时系统中,任务的截止期限是绝对的,任务必须在其截止期限之前完成,否则会导致系统的故障或错误。硬实时系统通常用于对实时性要求非常高的应用,如航空航天、医疗设备、工业控制等。举例:在一个飞行控制系统中,飞机需要按照严格的时间表执行各种飞行指令。例如,飞机在规定的时间内进行自动起飞、自动降落等任务。在这种情况下,任务的截止期限是绝对的,必须在预定的时间内完成,以确保飞行安全和准确性。 -
软实时系统(Soft Real-Time System):软实时系统也有实时性要求,但对任务的响应时间要求相对较宽松。在软实时系统中,任务的截止期限是相对的,如果任务没有在截止期限内完成,系统可以继续运行,但可能会导致性能下降或质量降低。软实时系统通常用于对实时性要求较低、更关注系统的效率和性能的应用,如多媒体系统、网络通信等。举例:在一个视频会议系统中,实时传输和显示视频是重要的,但对于视频帧的到达时间没有严格的要求。如果一个视频帧在一定时间内到达,系统可以继续播放后续的视频帧,尽管可能会导致一些视频延迟。在这种情况下,任务的截止期限是相对的,系统可以在一定程度上容忍延迟。
总体而言,硬实时系统对任务的截止期限有严格要求,必须在规定的时间内完成,而软实时系统的任务截止期限相对宽松,任务的延迟可以被容忍。根据具体的应用需求和实时性要求,选择合适的实时系统类型非常重要。
-
-
什么是设备驱动程序?它们在操作系统中的作用是什么?
参考答案
设备驱动程序是一种软件模块,用于操作系统与硬件设备之间的通信和交互。它们充当了操作系统与硬件设备之间的桥梁,使操作系统能够管理和控制各种硬件设备。设备驱动程序的作用包括:
硬件抽象:设备驱动程序提供了一种统一的接口,将硬件设备的复杂性和特定细节隐藏在底层。它们将硬件的操作细节抽象出来,使操作系统能够以一致的方式与不同类型的设备进行通信。设备管理:设备驱动程序负责设备的初始化、配置和管理。它们向操作系统提供了对设备资源的访问和控制,包括设备的启动、停止、中断处理等。数据传输:设备驱动程序处理数据在计算机系统和设备之间的传输。它们负责数据的读取和写入,将应用程序的数据请求转换为硬件设备的操作。错误处理:设备驱动程序监测和处理与硬件设备相关的错误和异常情况。它们负责处理设备故障、错误状态和异常事件,确保系统的稳定性和可靠性。性能优化:设备驱动程序可以通过优化设备的使用和数据传输方式来提高系统性能。它们可以使用各种技术和策略来最大限度地利用设备的性能潜力,减少资源的浪费和延迟。
参考资料:
-
什么是系统调用?它们在操作系统中的作用是什么?
参考答案
- 系统调用是什么:系统调用是操作系统提供给应用程序的编程接口,应用程序可以通过系统调用请求操作系统提供的服务和功能。它们是应用程序与操作系统之间的桥梁,允许应用程序访问底层的操作系统资源和执行特权操作。
- 系统调用的作用是什么:系统调用的作用是使应用程序能够执行与操作系统相关的操作,例如文件操作、进程管理、网络通信、内存管理等。通过系统调用,应用程序可以向操作系统发出请求,以获得所需的服务和资源。系统调用通常提供了一系列参数,应用程序可以设置这些参数来指定所需的操作和数据。
- 系统调用的工作原理:操作系统在收到系统调用请求时,会切换到内核模式,并执行相应的内核代码来满足应用程序的请求。内核会进行必要的权限检查和资源管理,以确保系统的安全性和稳定性。一旦操作完成,操作系统将结果返回给应用程序,并将控制权转回用户模式,应用程序继续执行。
操作系统内存及存储管理知识
-
什么是内存映射?为什么在嵌入式系统中使用内存映射?
参考答案
内存映射是一种将物理内存或设备寄存器映射到逻辑地址空间的技术。通过内存映射,物理内存和设备寄存器被映射为逻辑地址,使得处理器和其他系统组件可以通过逻辑地址来访问它们。在嵌入式系统中使用内存映射有以下几个原因:
统一访问接口:通过内存映射,嵌入式系统可以将外设的寄存器和物理内存映射到统一的逻辑地址空间中。这样,处理器可以使用相同的指令和地址访问这些设备,无需编写特定的设备驱动程序。这种统一的访问接口简化了系统设计和软件开发。简化访问操作:内存映射使得对外设寄存器的访问变得像对内存的访问一样简单。处理器可以使用读写内存的指令来读取和写入设备寄存器的值,从而简化了对外设的控制和配置。内存保护和安全性:内存映射可用于实现内存保护和安全性。通过将不同的内存区域映射到不同的地址空间中,并设置相应的访问权限,可以限制对某些关键数据和代码的访问。这提高了系统的安全性,并防止对内存的非法访问和修改。虚拟内存管理:内存映射还可用于虚拟内存管理。通过将物理内存映射到虚拟地址空间中,嵌入式系统可以实现虚拟内存的功能,包括内存分页、页面置换和内存共享等。这提供了更灵活和高效的内存管理机制,使系统能够有效地利用有限的物理内存资源。
参考资料:
-
解释闪存和EEPROM在嵌入式系统中的作用,并比较它们之间的区别。
参考答案
闪存和EEPROM(Electrically Erasable Programmable Read-Only Memory)都是在嵌入式系统中常见的非易失性存储器,它们在系统中具有不同的作用和特点。
-
闪存:闪存是一种非易失性存储器,常用于存储程序代码、操作系统和数据。它具有快速的读取速度和较大的存储容量,通常以块的形式进行读写操作。闪存具有擦除和编程的功能,允许数据被修改和更新。闪存通常分为 NOR Flash 和 NAND Flash 两种类型,它们在性能和应用场景上有所区别。在嵌入式系统中,闪存被广泛用于存储系统的固件、引导程序和应用程序等。它可提供长期存储和持久性的数据存储,确保系统在断电后能够保留数据和程序代码。闪存还具有较快的读取速度,支持随机访问,适用于需要频繁读取和写入数据的场景。 -
EEPROM:EEPROM是一种电可擦除可编程只读存储器,它与闪存相似,但在擦除和编程方面更加灵活。EEPROM可以以字节的形式进行读写操作,而不需要擦除整个块。这使得EEPROM适用于频繁写入和更新数据的应用。在嵌入式系统中,EEPROM常用于存储配置数据、校准参数、设备状态和用户设置等。它可提供可编程的存储空间,允许数据在系统运行时被动态地修改和更新。由于EEPROM支持字节级的读写操作,它特别适用于存储小量数据的场景。
区别:
存储方式:闪存以块的形式进行读写操作,而EEPROM以字节的形式进行读写操作。擦除和编程:闪存通常需要整个块进行擦除和编程,而EEPROM可以在字节级别进行擦除和编程。容量和性能:闪存通常具有较大的存储容量和更快的读取速度,而EEPROM容量较小且读取速度较慢。应用场景:闪存适用于存储程序代码和大容量数据的场景,而EEPROM适用于存储配置数据和小容量数据的场景。
参考资料:
-
-
解释内存管理和虚拟内存的概念及其在操作系统中的作用.
参考答案
-
内存管理是操作系统中的一个关键组成部分,用于管理计算机系统中的内存资源。它负责跟踪和分配内存,以满足进程和系统的内存需求,并确保不同进程之间不会相互干扰。其在操作系统中的作用是:内存分配和回收:内存管理负责分配和回收进程所需的内存空间。它跟踪空闲内存块并进行分配,确保每个进程得到所需的内存资源。内存保护:内存管理通过分配内存空间并为每个进程建立地址映射表,确保每个进程只能访问其自己的内存空间,从而实现内存的隔离和保护。
-
虚拟内存是一种内存管理技术,它将计算机的物理内存和磁盘上的虚拟内存空间进行映射和管理。它使得每个进程拥有独立的地址空间,从而提供了更大的可用内存空间。虚拟内存允许进程使用超过实际物理内存容量的内存,将不常用的数据存储在磁盘上,并通过页面调度算法将其加载到物理内存中。其在操作系统中的作用是:虚拟内存管理:虚拟内存技术使得系统可以在有限的物理内存情况下运行更多的进程,并提供了更大的地址空间。它通过将不常用的数据存储在磁盘上,将内存需求高效地管理起来。页面调度和换入/换出:虚拟内存使用页面调度算法决定哪些页面需要置换到磁盘上,以及何时将其换入物理内存。这些算法根据访问模式和优先级来优化内存的使用效率和性能。
参考资料:
-
-
解释操作系统中的文件系统和存储管理。
参考答案
文件系统:文件系统是操作系统用于组织和管理文件和目录的方法。它定义了文件的命名规则、存储结构、访问权限和操作方式等。文件系统提供了对文件和目录的创建、读取、写入、删除和修改等操作,并提供了文件的组织结构和层次化的目录结构。文件系统使用户和应用程序能够方便地管理和访问存储在磁盘或其他存储介质上的数据。存储管理:存储管理是操作系统对计算机系统中的物理存储资源进行管理和分配的过程。它负责将计算机系统的内存和磁盘等存储设备分配给进程和文件,并管理它们的使用和释放。存储管理包括内存管理和磁盘管理两个方面:内存管理:操作系统负责将有限的内存资源分配给运行的进程,并跟踪每个进程使用的内存区域。它提供了内存分配、地址映射、内存保护和页面置换等功能,以优化内存的利用和进程的执行。磁盘管理:操作系统管理磁盘上的文件和空闲空间。它负责文件的存储和组织,实现文件的读取和写入,并处理文件的空间分配和回收。磁盘管理使用文件系统来组织和管理文件,并使用磁盘调度算法来优化磁盘访问的效率。
-
什么是虚拟内存和物理内存?它们之间的映射关系是怎样的?
参考答案
物理内存是计算机硬件中用于存储数据和指令的实际硬件内存。它是由随机存取存储器(RAM)组成的,以字节为单位存储数据。物理内存是实际存在于计算机系统中的存储区域,用于存储正在运行的程序、操作系统和其他数据。虚拟内存是一种在操作系统层面上提供的抽象概念,它扩展了物理内存的容量。虚拟内存使用硬盘上的一部分空间作为辅助存储区域,并将其视为扩展的内存。通过虚拟内存,每个进程都拥有自己的虚拟地址空间,可以访问比物理内存更大的地址范围。- 虚拟内存和物理内存之间的映射关系是
通过操作系统的内存管理单元(MMU)来实现的。MMU负责将进程的虚拟地址转换为物理地址。具体工作流程原理如下:- 当进程访问虚拟内存中的数据时,MMU将虚拟地址划分为页面(通常是固定大小的块),然后将这些页面映射到物理内存中的对应位置。这样,虚拟内存中的页面可以分散地存储在物理内存中的不同位置。当进程访问虚拟内存中的某个页面时,MMU会将对应的物理地址提供给内存控制器,从而读取或写入真正的物理内存。
- 虚拟内存的映射关系可以动态地进行调整,以便在物理内存不足时进行页面置换(将不常用的页面从物理内存移到磁盘),从而为进程提供更大的地址空间。当进程访问被置换到磁盘上的页面时,操作系统会将该页面重新调入物理内存,并更新虚拟内存的映射关系。
参考资料:
-
解释分页和分段的内存管理方式。
参考答案
分页和分段是操作系统中常用的内存管理方式,用于将进程的虚拟地址映射到物理内存。
分页(Paging):在分页内存管理方式中,虚拟地址空间和物理内存都被划分为固定大小的页面(通常是4KB或8KB)。虚拟地址空间中的每个页面被映射到物理内存中的一个页面。这种映射是通过页表来实现的,页表存储了虚拟页面和物理页面之间的映射关系。当进程访问一个虚拟地址时,操作系统使用虚拟地址的高位来索引页表,找到对应的页表项,其中包含了物理页面的地址。通过将虚拟地址的低位与页表项中的偏移量进行组合,就可以得到对应的物理地址。分页的优点是地址空间的连续性和共享页面的能力,但也会带来内部碎片和页表的开销。分段(Segmentation):在分段内存管理方式中,虚拟地址空间和物理内存都被划分为不同大小的段。每个段都有一个基址和长度,表示该段在物理内存中的起始位置和长度。虚拟地址空间中的每个段被映射到物理内存中的一个段。当进程访问一个虚拟地址时,操作系统使用虚拟地址的段选择子来索引段描述符表,找到对应的段描述符,其中包含了物理段的基址和长度。通过将虚拟地址的偏移量与段描述符中的基址进行组合,就可以得到对应的物理地址。分段的优点是灵活的地址空间分配和保护,但也会带来外部碎片和段表的开销。
这两种内存管理方式通常可以结合使用,形成分页与分段的混合方式,称为分页段式内存管理。
参考资料:
操作系统线程及进程知识
-
在嵌入式系统设计中,如何处理并发任务和资源共享的问题?
参考答案
在嵌入式系统设计中,处理并发任务和资源共享的问题是非常重要的。以下是几种常见的方法和技术:
任务调度:使用实时操作系统(RTOS)来管理和调度任务。RTOS提供了任务调度器,可以根据任务的优先级和调度策略决定任务的执行顺序。任务调度器会根据预定的调度算法将处理器时间分配给不同的任务,以实现并发执行。同步和互斥:使用同步机制和互斥机制来控制任务之间的访问和共享资源。常用的同步机制包括信号量(Semaphore)和事件(Event),它们可以用于任务之间的通信和同步操作。互斥机制例如互斥量(Mutex)和临界区(Critical Section),用于保护共享资源的访问,确保同时只有一个任务能够访问该资源。中断处理:使用中断来处理紧急事件和异步操作。中断允许系统在发生外部事件时立即响应,并暂停当前任务执行,执行中断服务程序。中断服务程序通常是短小而快速的,用于处理特定的事件或任务,并在完成后恢复原来的任务执行。状态机设计:使用状态机来管理并发任务和状态转换。状态机是一种有限状态机(FSM)的设计模式,通过定义状态和状态转换条件,控制任务的行为和状态切换。状态机设计可简化任务之间的协调和控制,并提高系统的可维护性。
-
在嵌入式软件开发中,如何处理实时任务的优先级和调度?
参考答案
在嵌入式软件开发中,处理实时任务的优先级和调度是确保系统能够满足实时性要求的重要部分。以下是一些常见的方法和技术:
- 优先级分配:为每个实时任务分配适当的优先级,根据任务的紧急程度和重要性确定其执行顺序。通常,优先级较高的任务会在优先级较低的任务之前执行。
- 调度算法:选择合适的调度算法来决定任务的执行顺序。常用的调度算法包括先来先服务(FCFS)、最短作业优先(SJF)、优先级调度、循环调度(Round-Robin)等。根据系统需求和任务特点选择合适的调度算法。
- 中断处理:对于具有实时要求的任务,使用中断来响应外部事件或触发条件。中断处理可以立即打断当前任务的执行,执行紧急的任务,然后返回原来的任务继续执行。
- 资源管理和互斥:确保共享资源的安全访问和避免竞争条件。使用互斥锁、信号量、事件标志等机制来实现对共享资源的互斥访问和同步。
- 实时任务设计:在设计实时任务时,要考虑任务的执行时间、截止期限、依赖关系等因素。确保任务能够在规定的截止期限内完成,并满足实时性要求。
- 性能分析和调试工具:使用性能分析工具和调试工具来监测和分析实时任务的执行情况,识别潜在的性能问题和调度延迟,并进行优化和调试。
实时任务的优先级和调度的设计需要根据具体的系统需求和实时性要求进行权衡和选择。同时,合适的任务划分、优先级分配和调度算法的选择也取决于嵌入式系统的硬件平台和应用场景。
-
请解释抢占式调度和非抢占式调度的区别。
参考答案
抢占式调度和非抢占式调度是操作系统中用于管理任务和资源分配的两种不同策略。
抢占式调度是指操作系统能够强制中断当前正在执行的任务,并将CPU资源分配给更高优先级的任务。在抢占式调度中,任务的执行顺序可以在任何时候被打断,无论任务是否已经完成。这种调度策略使得操作系统能够对任务进行更精确的控制,提高系统的响应速度和吞吐量。然而,频繁的抢占也可能引起任务切换的开销,降低系统的效率。非抢占式调度是指任务在开始执行后,只有在任务主动释放CPU资源或者任务执行完毕后,操作系统才会将CPU资源分配给下一个任务。在非抢占式调度中,任务具有更长的执行时间,减少了任务切换的开销。但是,如果一个任务占用了过长时间的CPU资源,其他高优先级的任务可能会等待很长时间才能执行,从而降低了系统的响应速度。总之,抢占式调度和非抢占式调度的区别在于
任务是否可以在任意时刻被强制中断。抢占式调度提供了更灵活的任务管理和更快的响应能力,但可能引起更多的开销;非抢占式调度则具有更低的开销,但可能导致任务响应时间较长。参考资料:
-
解释进程和线程的概念,并比较它们之间的区别。
参考答案
进程和线程是操作系统中用于执行任务的两个基本概念:
-
进程是计算机中的一个执行单元,是程序在执行过程中分配和管理资源的基本单位。每个进程都有自己的地址空间、内存、文件描述符和其他系统资源。进程之间相互独立,它们在操作系统中以独立的实体存在,并且通过进程间通信(IPC)机制进行交互。
-
线程是进程的子任务或执行路径,是进程中的实际执行单位。一个进程可以拥有多个线程,它们共享相同的地址空间和系统资源。线程可以同时执行多个任务,使得程序能够实现并发执行和多线程处理。线程间的切换开销较小,因为它们共享了进程的上下文。
区别:
资源分配:进程拥有独立的资源分配,包括内存空间、文件描述符等;而线程共享所属进程的资源,如内存空间、文件和网络连接等。调度和切换:进程间的切换开销较大,需要保存和恢复整个进程的上下文信息;线程间的切换开销较小,因为它们共享进程的上下文,只需要切换线程的私有数据和栈。并发性和执行速度:由于线程共享资源,线程间的通信和同步较为方便,可以实现更高的并发性;而进程之间的通信和同步开销较大。另外,线程的创建、销毁和切换速度较快,因此线程的执行速度一般比进程快。
参考资料:
-
-
什么是同步和互斥?如何实现线程同步和互斥?
参考答案
同步和互斥是计算机科学中常见的概念,用于控制多个线程或进程之间的访问和操作。
互斥是指在同一时刻只允许一个访问者对资源进行访问,具有排它性。同步是指在互斥的基础上,通过其他机制实现访问者对资源的有序访问。在大多数情况下,同步已经实现了互斥。
线程同步和互斥可以通过以下方式实现:
互斥锁(Mutex):互斥锁是一种常见的同步机制,通过在关键代码段前后加锁和解锁操作,确保在同一时间只有一个线程访问共享资源。适用于对共享资源的访问时间较短的情况。信号量(Semaphore):信号量是一种计数器,用于控制对共享资源的访问。它可以允许多个线程同时访问资源,也可以限制同时访问的线程数。适用于对共享资源的访问时间较长的情况。条件变量(Condition Variable):条件变量用于在线程之间进行等待和通知。线程可以等待某个条件变量满足特定条件,当条件满足时,其他线程可以发出通知来唤醒等待的线程。适用于需要等待某个条件满足后才能继续执行的情况。读写锁(Read-Write Lock):读写锁允许多个线程同时对共享资源进行读取操作,但只允许一个线程进行写操作。这可以提高读操作的并发性能。适用于读操作比写操作多的情况。
参考资料:
-
请解释操作系统中的进程间通信(IPC)的概念和常见的 IPC 机制。
参考答案
进程间通信(IPC)是指在操作系统中,不同进程之间进行数据交换和通信的机制和技术。多个进程之间可能需要相互协作、共享数据或传递消息,以完成特定的任务或实现系统功能。为了实现进程间的通信,操作系统提供了各种IPC机制。常见的IPC机制包括:
管道(Pipe):管道是一种单向的通信机制,可以在具有父子关系的进程之间进行通信。它提供了一个字节流的缓冲区,一个进程将数据写入管道的一端,另一个进程从另一端读取数据。命名管道(Named Pipe):命名管道也是一种单向的通信机制,但不限于具有父子关系的进程。不同进程可以通过共享一个命名管道来进行通信,进程可以在管道上进行读写操作。信号量(Semaphore):信号量是一种用于进程同步和互斥的通信机制。它可以用来解决进程之间的竞争条件和资源共享的问题。进程可以使用信号量进行互斥访问,控制对临界资源的访问。消息队列(Message Queue):消息队列是一种在进程之间传递消息的通信机制。它通过在消息队列中存储消息,使多个进程可以异步地进行通信。每个消息都具有特定的类型和优先级。共享内存(Shared Memory):共享内存是一种高效的进程间通信机制,它允许多个进程共享同一块物理内存区域。进程可以直接访问和修改共享内存中的数据,而无需进行数据的拷贝和传输。套接字(Socket):套接字是一种用于网络通信的IPC机制,它提供了一种标准的网络编程接口。通过套接字,进程可以在不同主机之间进行通信,实现网络应用程序。
-
解释一下信号量和互斥锁的概念以及它们在多任务环境中的应用
参考答案
信号量(Semaphore)和互斥锁(Mutex)是在多任务环境中用于同步和互斥访问共享资源的机制。
-
信号量(Semaphore):信号量是一种计数器,用于控制对共享资源的访问。它可以是整数类型的变量,用于记录资源的可用数量或可访问状态。信号量具有两个基本操作:等待(wait)和通知(signal)。- 等待(wait)操作:如果信号量的值大于零,则减少其值并继续执行。如果值为零,则等待其他任务释放资源,并阻塞当前任务。
- 通知(signal)操作:增加信号量的值,表示资源已经可用,并通知等待的任务继续执行。
-
互斥锁(Mutex):互斥锁是一种二进制标志,用于保护共享资源的独占访问。它具有两个状态:锁定(locked)和解锁(unlocked)。- 锁定状态:当一个任务获得互斥锁时,其他任务尝试获得该锁将被阻塞,直到持有锁的任务释放锁。
- 解锁状态:当持有锁的任务释放锁时,其他被阻塞的任务可以尝试获得该锁并继续执行。
应用场景:
- 信号量:信号量的应用场景包括资源池管理、任务调度、进程间通信等。它可以确保在多个任务同时访问共享资源时,对资源的访问是互斥的或受限的。
- 互斥锁:互斥锁通常用于保护临界区,即一段需要互斥访问的代码区域。它可以确保在同一时间只有一个任务可以执行临界区代码,从而避免竞态条件和数据一致性问题。
-
操作系统中断知识
-
什么是中断?在嵌入式系统中,为什么中断很重要?
参考答案
中断是计算机系统中的一种机制,用于在当前执行的程序或任务被中断处理程序(Interrupt Service Routine,ISR)中断执行时,响应和处理发生的事件或信号。在嵌入式系统中,中断非常重要的原因包括:
实时响应:嵌入式系统通常需要实时响应外部事件,如传感器输入、通信数据到达等。中断允许系统立即中断当前任务的执行,转而处理紧急事件,从而满足实时性要求。异步处理:中断机制可以处理异步事件,这些事件无法通过程序的顺序执行来预测。通过中断,系统可以立即响应和处理这些事件,而无需等待主程序轮询或检查。多任务处理:中断机制使得多个任务能够并发地运行。当一个任务被中断时,系统可以立即切换到另一个任务,并在中断处理完成后返回到中断之前的执行状态。事件驱动:嵌入式系统通常是事件驱动的,即通过检测和处理事件来触发特定的操作。中断机制使得系统能够及时响应和处理这些事件,从而实现事件驱动的功能。
-
请解释中断处理和中断服务程序的概念
参考答案
中断是计算机系统中的一种机制,用于向CPU发出异步信号,以通知操作系统发生了某种事件,例如外部设备完成了输入/输出操作或发生了错误。中断可以打断正在执行的程序,并立即转移到相应的中断服务程序中进行处理。中断处理是指操作系统对中断事件的响应和处理过程。当发生中断时,CPU会立即中断当前正在执行的任务,并转到与中断事件相关的中断服务程序。中断处理程序负责处理中断事件,保存当前任务的上下文,执行中断服务程序,处理中断事件后恢复上下文并返回到原任务。中断服务程序是与特定中断事件相关联的程序,它负责处理特定的中断事件。每个中断事件都有一个唯一的中断向量或中断号,操作系统根据中断号找到对应的中断服务程序。中断服务程序通常是预先定义好的,它们执行特定的操作来处理中断事件,例如读取设备数据、响应用户输入等。
-
解释操作系统中的信号和信号处理程序的概念。
参考答案
- 在操作系统中,
信号是一种用于通知进程发生某个事件或异常情况的机制。它是一种软件中断,可以从内核(操作系统的核心)发送给进程。当发生某个特定的事件或条件时,内核可以向进程发送一个信号,进程可以捕获并处理该信号。 信号处理程序是一个用于处理接收到的信号的特殊函数。当进程接收到一个信号时,操作系统会将控制权转移到相应的信号处理程序,该程序执行与信号相关的操作。信号处理程序可以执行各种操作,如捕获和处理异常、记录日志、执行特定的操作等。
信号和信号处理程序在操作系统中起到以下作用: 3.
异常处理:当进程遇到错误或异常情况时,操作系统可以向进程发送相应的信号,使得进程能够捕获并处理这些异常,保证程序的稳定性和可靠性。 4.事件通知:操作系统可以向进程发送信号,通知其发生了某个特定的事件,如键盘输入、鼠标点击等。进程可以捕获这些信号并作出相应的响应。 5.进程间通信:进程可以使用信号进行通信。一个进程可以向另一个进程发送信号,请求某种操作或提醒对方发生了某个事件。 - 在操作系统中,
-
介绍中断向量表和中断优先级的概念。
参考答案
中断向量表(Interrupt Vector Table)是操作系统用于管理和响应中断的数据结构。它是一个预先定义的表格,存储了每个中断类型对应的中断处理程序的入口地址。当发生一个中断时,硬件会通过中断控制器将中断信号发送给操作系统。操作系统根据中断类型,在中断向量表中查找相应的中断处理程序的入口地址,并跳转到该地址开始执行中断处理程序。中断向量表的目的是为了提供一种快速的、固定的方式来寻找中断处理程序,以实现对中断的及时响应。每个中断类型在中断向量表中有一个唯一的入口地址,操作系统可以根据需要为每个中断类型编写相应的处理程序,并将其地址存储在中断向量表中。中断优先级是用于确定中断响应顺序的概念。当多个中断同时发生时,中断控制器会根据中断优先级来确定哪个中断被优先处理。较高优先级的中断将中断较低优先级的中断,并立即处理该中断。中断优先级通常由硬件或操作系统设定,并可以根据需要进行配置和调整。
参考资料:
ARM体系架构基础知识
-
什么是ARM架构?它有哪些特点和优势?
参考答案
ARM架构(Advanced RISC Machine)是一种处理器架构,广泛应用于移动设备、嵌入式系统和低功耗应用中。以下是ARM架构的一些特点和优势:
简化指令集:ARM采用精简指令集(RISC, Reduced Instruction Set Computer),指令集简单且易于解码和执行,使得处理器设计更加高效。低功耗设计:ARM架构在设计上注重低功耗特性,使得ARM处理器能够在电池供电的移动设备上实现较长的续航时间。高性能:尽管ARM架构着重于低功耗设计,但它也能提供出色的性能。ARM处理器通过多核设计、高频率运行和高级优化技术,实现了高效的计算能力。可扩展性:ARM架构具有良好的可扩展性,可以应用于不同的设备和应用领域。从低端的嵌入式系统到高端的服务器,ARM处理器都能够满足各种需求。软件生态系统:ARM架构享有广泛的软件生态系统支持。许多操作系统(如Android、iOS)和应用程序已经针对ARM架构进行了优化,使得ARM处理器成为移动设备的首选。设计定制性:ARM架构提供了灵活的设计定制选项,使得芯片制造商能够根据特定应用的需求进行定制和优化,从而实现更好的性能和功耗平衡。
参考资料:
-
ARM体系结构的版本有哪些?它们之间有什么区别?
参考答案
ARM体系结构有多个版本,其中一些主要版本包括:
- ARMv1:最早的ARM体系结构版本,于1985年发布。它使用了32位的精简指令集。
- ARMv2:于1986年发布,增加了一些新的指令和功能。
- ARMv3:于1992年发布,引入了Thumb指令集,该指令集使用16位指令,用于提高代码密度。
- ARMv4:于1994年发布,增加了更多指令和功能,如支持Java虚拟机(Jazelle)和分页内存管理。
- ARMv5:于1997年发布,引入了更多指令和功能,包括协处理器支持、增强的分页内存管理和增强的Thumb指令集。
- ARMv6:于2002年发布,引入了Thumb-2指令集,该指令集能够同时支持16位和32位指令。
- ARMv7:于2005年发布,包括多个变体,如ARMv7-A(应用程序处理器)、ARMv7-R(实时处理器)和ARMv7-M(微控制器)。ARMv7架构增加了更多指令和功能,如NEON(SIMD指令集扩展)和虚拟化支持。
- ARMv8:于2011年发布,引入了AArch64(64位执行状态),与之前的ARMv7架构兼容。ARMv8还包括一些新的特性,如更高的性能、更大的虚拟地址空间和更丰富的加密支持。
- ARMv9:于2021年发布,引入了许多新的功能,如Confidential Compute Architecture(机密计算架构)、Realms(安全执行环境)和SVE2(可扩展向量扩展2)等。
这些不同版本的ARM体系结构之间的区别主要体现在指令集、功能和架构特性方面。每个版本都对之前的版本进行了改进和扩展,以提供更高的性能、更丰富的功能和更好的能效。
参考资料:
-
请解释一下ARM处理器的体系结构,包括处理器模式、寄存器和指令集等。
参考答案
-
处理器模式:ARM处理器有多个处理器模式,每个模式用于执行不同类型的任务。常见的处理器模式包括:
- 用户模式(User Mode):用户模式是一种常规模式,用于执行应用程序。在用户模式下,处理器的权限较低,无法直接执行特权指令或访问受保护的系统资源。它是最受限制的模式。
- 系统模式(System Mode):运行具有特权的操作系统任务。
- 管理模式(Supervisor mode):操作系统使用的保护模式。在系统复位或执行软件中断指令SWI时进入。
- 中止模式(Abort mode):当数据或指令预取终止时进入该模式,可用于虚拟存储及存储保护。
- 未定义模式(Undefined mode):当未定义的指令执行时进入该模式,可用于支持硬件协处理器的软件仿真。
- 快速中断模式(FIQ mode):用于高速数据传输或通道处理。
- 外部中断模式(IRQ mode):用于通用的中断处理。
- 模式(Hyp mode):用于虚拟化环境中的虚拟化监管。
-
寄存器:ARM处理器有多个寄存器,用于存储和处理数据。常见的寄存器包括:
- 通用寄存器(General-Purpose Registers):用于存储临时数据和计算结果。
- 程序计数器(Program Counter,PC):存储当前正在执行的指令的地址。
- 程序状态寄存器(Current Program Status Register, CPSR):存储处理器的状态信息,如处理器模式、中断使能等。
- 程序状态保存寄存器(Saved Program Status Registers, SPSR):当异常发生时,用于存储CPSR信息。
-
指令集:ARM处理器使用ARM指令集和Thumb指令集。
- ARM指令集包含32位的指令,提供了丰富的功能和灵活性。
- Thumb指令集支持16位的指令,用于提高代码密度和节省存储空间。
- 最新的ARM处理器还支持AArch64执行状态,提供了64位的指令集,称为AArch64指令集。
参考资料:
-
-
什么是Thumb指令集?与ARM指令集有什么区别?
参考答案
Thumb指令集是ARM架构中的一种16位指令集,旨在提高代码密度和降低存储器需求。下面是Thumb指令集与ARM指令集的区别:
指令长度:ARM指令集的指令长度为32位,而Thumb指令集的指令长度为16位。由于指令长度减少了一半,Thumb指令集可以在同样的存储空间下存储更多的指令,从而提高了代码密度。寄存器数量:ARM指令集有16个通用寄存器,每个寄存器都是32位的。而Thumb指令集有8个通用寄存器,每个寄存器都是16位的。这意味着在Thumb指令集中,可以同时使用的寄存器数量更少,因此需要更频繁地进行数据的加载和存储。指令集功能:ARM指令集提供了更多的功能和灵活性,支持更多的数据处理操作和复杂的指令流控制。相比之下,Thumb指令集在设计上更加简化,提供了基本的数据操作和简单的控制流指令,牺牲了一些高级功能和复杂的指令。性能:由于Thumb指令集的指令长度较短,指令的执行时间通常也较短。因此,在某些情况下,Thumb指令集可以提供更高的执行速度和更低的功耗。
参考资料:
-
请介绍一下ARM的异常处理机制,包括中断和异常的区别以及处理过程。
参考答案
- 中断和异常的区别:
中断(Interrupt)是由外部设备或事件引发的中断请求,用于打断正在执行的指令流,让处理器转移到中断服务程序(Interrupt Service Routine,ISR)来处理该事件。中断通常由外部设备的信号触发,例如定时器溢出、外部设备的输入等。异常(Exception)是由程序运行过程中的异常情况引发的事件,如无效的指令、访问越界、除以零等。异常会导致处理器从当前模式切换到异常模式,并执行异常处理程序(Exception Handler)来处理异常情况。
- 异常处理过程:
- 当发生异常时,处理器会保存当前的上下文信息(如寄存器状态、程序计数器等),以便稍后恢复执行。
- 处理器会根据异常类型和优先级判断是否响应该异常,如果需要响应,则会切换到异常模式,并跳转到相应的异常处理程序。
- 异常处理程序会执行相关的异常处理逻辑,如错误处理、状态恢复、错误日志记录等。
- 在处理完异常后,处理器会从保存的上下文信息中恢复状态,并回到原来的模式和指令流中,继续执行。
参考资料:
- 中断和异常的区别:
-
什么是ARM的Cache和MMU?它们在系统中的作用是什么?
参考答案
Cache:Cache是一种位于处理器和主存之间的高速存储器,用于存储最近使用的数据和指令。它的作用是通过预先将数据和指令复制到快速的缓存中,加快对数据的访问速度,减少对主存的访问次数。Cache的工作原理是基于局部性原理,即程序和数据的访问往往呈现出一定的空间局部性和时间局部性。Cache通过存储最近使用的数据块,以便在后续的访问中快速提供数据,减少了对主存的延迟。MMU:MMU是负责管理虚拟内存和物理内存之间映射关系的组件。它允许操作系统和应用程序使用虚拟内存地址,而不必关心物理内存的实际分配情况。MMU的主要功能包括地址转换和内存保护。它通过将虚拟地址转换为物理地址,实现了对虚拟内存的透明访问。MMU还负责内存保护,通过访问控制和权限设置,确保不同应用程序之间的内存隔离和安全性。MMU还支持内存映射技术,例如页面映射(Page Mapping)和段映射(Segment Mapping),以及虚拟内存的分页和分段机制,实现了灵活的内存管理和资源分配。
-
什么是ARM的大端和小端字节序?它们在ARM体系结构中的应用是什么?
参考答案
字节序(Byte Order)指的是多字节数据在内存中存储的顺序。
大端字节序:在大端字节序中,多字节数据的高位字节存储在低地址处,而低位字节存储在高地址处。这意味着多字节数据的字节顺序与其在内存中的存储顺序相同。小端字节序:在小端字节序中,多字节数据的低位字节存储在低地址处,而高位字节存储在高地址处。这意味着多字节数据的字节顺序与其在内存中的存储顺序相反。
在ARM体系结构中,字节序对于处理器和操作系统的开发者来说是重要的。不同的字节序可能会影响数据的读取和存储,特别是在跨平台和数据交换的情况下。
参考资料:
-
请介绍一下ARM的协处理器(Coprocessor)和向量处理器(NEON)
参考答案
协处理器(Coprocessor):协处理器是ARM处理器的一个可选扩展,用于执行特定的处理任务。它是与主处理器并行工作的一个辅助处理器。协处理器可以执行一些特定的指令和操作,例如浮点运算、加密算法、信号处理等。通过将特定任务分配给协处理器,ARM处理器可以提高处理性能和效率。向量处理器(NEON):NEON是ARM处理器中的一个向量处理器扩展,用于高效执行并行的多媒体和信号处理操作。NEON提供了一组特定的指令和寄存器,用于同时处理多个数据元素,例如矢量、矩阵和像素数据。这使得ARM处理器能够高效地执行诸如图像处理、音频处理、视频编解码等计算密集型任务。
参考资料:
-
解释一下ARM的体系结构中的模式和模式切换。
参考答案
ARM体系中的8种模式可见问题3,关于模式切换的解释如下:
模式切换是指从当前模式切换到另一个模式。ARM体系结构提供了一些特定的指令和方式来实现模式切换。例如,使用SVC(Supervisor Call)指令可以从用户模式切换到管理模式,而使用SWI(Software Interrupt)指令可以从用户模式切换到中断模式。
在模式切换时,当前模式的寄存器状态将保存在相应的模式特定的寄存器集中,然后加载目标模式的寄存器状态。这样可以确保在不同的模式之间切换时,不会丢失关键的状态信息。模式切换还会改变处理器的特权级别,从而决定哪些指令和资源可以被访问和执行。
-
请解释一下ARM处理器的管道流水线和流水线相关的概念
参考答案
ARM处理器的管道流水线是一种用于提高指令执行效率的技术。它将指令执行过程划分为多个阶段,并在每个阶段引入寄存器,使得多条指令可以同时在不同的阶段执行。这样可以提高处理器的吞吐量,使得指令能够更快地完成执行。
流水线中的不同阶段包括:
- 取指令(Instruction Fetch)
- 译码(Instruction Decode)
- 执行(Execute)
- 访存(Memory Access)
- 写回(Write Back)
每个阶段负责不同的任务,并且通过寄存器传递结果到下一个阶段。
通过流水线技术,当一条指令执行进入流水线后,后续的指令可以继续进入流水线的不同阶段,从而实现指令级并行(Instruction-Level Parallelism)。这可以提高处理器的效率,使得多条指令可以在同一时间段内重叠执行。
参考资料:
-
什么是ARM中断控制器(Interrupt Controller)?举例说明如何处理中断。
参考答案
ARM中断控制器(Interrupt Controller)是ARM处理器中的一个重要组件,用于管理和处理中断信号。它负责接收来自外部设备或内部事件的中断请求,并根据优先级和配置信息将中断信号传递给处理器核心。
下面是一个简单的示例,说明ARM中断控制器如何处理中断:
- 外部设备发出中断请求信号,例如一个键盘按键被按下。
- 中断控制器接收到中断请求信号,并根据预先配置的中断优先级判断该中断的优先级。
- 如果该中断的优先级高于当前正在处理的中断,中断控制器将中断请求传递给处理器核心。
- 处理器核心响应中断,暂停当前的指令执行,并跳转到中断处理程序的入口地址。
- 中断处理程序执行相应的处理操作,例如读取键盘输入数据。
- 处理完成后,中断处理程序返回到中断发生前的指令位置,恢复之前的执行状态。
- 中断控制器通知处理器中断处理结束,并可以选择响应下一个优先级较高的中断请求。
-
ARM体系结构中的Thumb-2技术是什么?它如何提高代码密度和性能?
参考答案
Thumb-2是ARM体系结构中的一种指令集技术,旨在提高代码密度和性能。它结合了Thumb指令集(16位指令)和ARM指令集(32位指令),使得处理器能够同时执行16位和32位指令,以适应不同的应用场景。Thumb-2技术提供了以下优势:
代码密度改善:Thumb-2指令集中的16位指令相比于32位指令更加紧凑,占用更少的存储空间。通过使用Thumb-2指令集,可以显著减少程序的代码大小。这对于存储有限的设备(如嵌入式系统)和带宽受限的环境非常有益。性能提升:Thumb-2技术不仅仅是为了减少代码大小,还针对性能进行了优化。Thumb-2指令集中的某些16位指令具有与对应的32位指令相似的执行效率。这意味着通过使用Thumb-2指令集,可以在减少代码大小的同时保持较高的执行效率。兼容性和灵活性:Thumb-2技术兼容先前的Thumb指令集,因此可以无缝地与使用Thumb指令集编写的现有代码进行交互。此外,处理器可以在Thumb状态和ARM状态之间进行快速切换,使得开发人员可以根据需要选择最适合的指令集。
-
ARM处理器的访存模型是什么?它与虚拟内存有什么关系?
参考答案
- ARM的访存模型:ARM处理器采用了一种称为“Harvard结构”的访存模型,其中指令和数据分别存储在不同的内存空间中。 中央处理器首先到程序指令储存器中读取程序指令内容,解码后得到数据地址,再到相应的数据储存器中读取数据,并进行下一步的操作(通常是执行)。程序指令储存和数据储存分开,数据和指令的储存可以同时进行,可以使指令和数据有不同的数据宽度,
- 与虚拟内存的关系:ARM处理器与虚拟内存之间的关系是通过内存管理单元(MMU)来实现的。MMU负责将程序中的虚拟地址转换为物理地址。在访问内存时,ARM处理器使用虚拟地址进行操作,然后MMU根据映射表(Page Table)将虚拟地址转换为物理地址。这种地址转换的过程是透明的,程序无需关心物理内存的实际布局。
参考资料:
-
ARM处理器的浮点运算支持是如何实现的?有哪些浮点运算指令?
参考答案
ARM处理器的浮点运算支持是通过
浮点单元(Floating-Point Unit,FPU)来实现的。FPU是一个硬件模块,专门用于执行浮点运算,包括浮点加减、乘除、取整等操作。ARM处理器中的浮点运算指令集被称为
VFP(Vector Floating-Point)指令集。VFP指令集提供了一系列的浮点运算指令,包括:- 浮点加减指令:用于执行浮点数的加法和减法操作。例如,VADD(浮点加法)和VSUB(浮点减法)指令。
- 浮点乘法指令:用于执行浮点数的乘法操作。例如,VMUL(浮点乘法)指令。
- 浮点除法指令:用于执行浮点数的除法操作。例如,VDIV(浮点除法)指令。
- 浮点取整指令:用于执行浮点数的取整操作,包括向下取整、向上取整、截断等。例如,VCVT(浮点取整)指令。
- 浮点比较指令:用于比较两个浮点数的大小。例如,VCMPE(浮点比较)指令。
- 浮点转换指令:用于执行不同浮点数格式之间的转换。例如,VCVT(浮点转换)指令。
- 浮点数据加载和存储指令:用于将浮点数据加载到寄存器或存储到内存。例如,VLDR(浮点加载)和VSTR(浮点存储)指令。
参考资料:
-
ARM处理器的功耗管理机制是如何工作的?有哪些方法可以降低功耗?
参考答案
ARM处理器采用了多种功耗管理机制来降低功耗并提高能效。这些机制旨在根据处理器的工作负载和需求动态调整处理器的性能和功耗。以下是一些常见的ARM处理器功耗管理机制和方法:
动态电压频率调节(Dynamic Voltage and Frequency Scaling,DVFS):DVFS允许处理器根据负载需求动态调整工作频率和电压。当处理器需要更高的性能时,可以增加工作频率和电压;当处理器处于轻负载或空闲状态时,可以降低工作频率和电压以降低功耗。休眠状态和低功耗模式:处理器可以进入休眠状态或低功耗模式,在这些状态下,处理器的工作频率和电压会被降低到最低限度,以节省功耗。当处理器再次需要被唤醒时,会恢复到正常工作状态。智能缓存和预取机制:处理器的缓存和预取机制可以提高数据访问效率,减少对主存的访问次数,从而降低功耗。智能缓存能够预测和缓存可能的数据访问模式,以提供更高的数据命中率和更低的功耗。功耗优化的指令调度和执行:处理器在指令调度和执行时可以采取一些技术来降低功耗。例如,乱序执行(Out-of-order Execution)可以在不影响程序正确性的前提下重排指令的执行顺序,以优化资源利用和降低功耗。硬件加速器和专用引擎:一些ARM处理器集成了硬件加速器和专用引擎,用于执行特定的计算任务(如加密、解压缩等),这些加速器和引擎通常比通用处理器更高效,可以降低功耗。功耗分析和优化工具:ARM提供了各种功耗分析和优化工具,开发人员可以使用这些工具来评估和优化处理器的功耗。这些工具可以帮助开发人员识别功耗热点、优化算法和代码,从而降低功耗。
参考资料:
-
什么是ARM的片上总线(AMBA)?它有哪些常见的版本?
参考答案
AMBA(Advanced Microcontroller Bus Architecture)是由ARM公司提出的一种片上总线协议和架构。它定义了一组标准接口和通信协议,用于连接和协调处理器内部的不同模块和外设。AMBA提供了一种灵活、可扩展和可重用的总线架构,使得不同模块和外设能够有效地进行数据传输和通信。它通过规范化接口和传输协议,简化了系统设计和集成的复杂性。常见的AMBA版本包括:
AMBA 2(Advanced Microcontroller Bus Architecture 2nd Generation):AMBA 2版本是AMBA总线的第二代,引入了两个主要的总线规范:AHB(Advanced High-performance Bus)和APB(Advanced Peripheral Bus): - AHB是一种高性能、低延迟的总线,用于连接高带宽和关键性能的模块,如处理器和高速存储器。 - APB是一种低带宽、低功耗的总线,用于连接较简单的外设,如GPIO(通用输入输出)和串口控制器。AMBA 3(Advanced Microcontroller Bus Architecture 3rd Generation):AMBA 3版本引入了新的总线规范:AXI(Advanced eXtensible Interface)。 - AXI是一种高性能、高带宽的总线,用于连接处理器、内存和高性能外设。它支持多主机、多从机配置,并具有更高的并行性和流水线能力。AMBA 4(Advanced Microcontroller Bus Architecture 4th Generation):AMBA 4版本引入了ACE(AMBA 4 Coherency Extensions)总线规范。 - ACE是AMBA 4协议的扩展版本,用于支持多核处理器系统中的一致性和高性能通信
参考资料: