C语言基础语法知识
-
C语言有哪些
存储类型(Storage Class)?参考答案
存储类型主要定义程序对象(变量及函数)的存储生命周期及作用域;C语言的四种存储类型及其生命周期和作用域分别为:
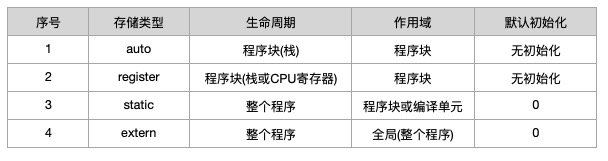
register修饰符有特殊的限制,具体如下:objects declared with the register storage class may be given higher priority by the compiler for access to registers; although the compiler may choose not to actually store any of them in a register. Objects with this storage class may not be used with the address-of (&) unary operator.即使用
register修饰的变量,会优先存储在CPU寄存器中(但不一定会存储在寄存器中,因为寄存器数量是有限的),而且该变量不能使用取地址符(&);参考资料:
-
C语言中
static关键字有哪些作用?参考答案
static修饰符可用于修饰全局变量、局部变量或函数,三种场景下的作用分别为:- 修饰全局变量时:被修饰的变量称为静态全局变量。该全局变量仅在当前文件内可见。
- 修饰局部变量时:被修饰的变量称为静态局部变量。变量仅初始化一次,而且由于变量是存储在数据段,而非堆或栈上,因此局部变量在离开作用域后不会被销毁,变量值始终有效直至程序结束。
- 修饰函数时:被修饰的函数称为静态函数。该函数仅在当前文件内可见。
参考资料:
-
是否可以在头文件中定义
static变量?参考答案
可以,但包含该头文件的源文件会有命名相同但实际不同的
static变量。参考资料:
-
volatile的作用是什么,什么时候需要使用volatile?参考答案
volatile修饰变量时表示变量的值可能有多个途径进行修改,尽管在代码上并没有显式修改变量值。因此volatile用于指示编译器针对所修饰的变量不要进行编译优化,防止编译器优化导致变量值的读写异常。举个简单的例子,以下代码中全局静态变量
b不使用volatile修饰:static int b; int main() { b = 1; while (b != 255) { ; } return 0; }其生成的二进制如下(使用gcc -O3):
Disassembly of section __TEXT,__text: 0000000000000000 <_main>: 0: 55 pushq %rbp 1: 48 89 e5 movq %rsp, %rbp 4: 66 2e 0f 1f 84 00 00 00 00 00 nopw %cs:(%rax,%rax) e: 66 90 nop 10: eb fe jmp 0x10 <_main+0x10>而加上
volatile修饰之后的,其二进制如下:Disassembly of section __TEXT,__text: 0000000000000000 <_main>: 0: 55 pushq %rbp 1: 48 89 e5 movq %rsp, %rbp 4: c7 05 fc ff ff ff 01 00 00 00 movl $1, -4(%rip) ## 0xa <_main+0xa> e: 66 90 nop 10: 8b 05 00 00 00 00 movl (%rip), %eax ## 0x16 <_main+0x16> 16: 3d ff 00 00 00 cmpl $255, %eax 1b: 75 f3 jne 0x10 <_main+0x10> 1d: 31 c0 xorl %eax, %eax 1f: 5d popq %rbp 20: c3 retq从生成的不同的二进制我们可以看到,不加
volatile修饰时,并没有比较b和255的值,即代码优化导致实际的代码逻辑出现异常。参考资料:
-
inline和macro在使用上有什么区别?参考答案
inline和macro均可以用于做代码的替换,这两者的差别主要有:- 代码展开的阶段不同。
macro在预处理阶段就进行展开,而inline在代码编译过程展开。 - 类型检查的要求不同。
macro并不做类型检查,而inline函数本身就是函数,会做类型检查。 - 表达式计算的方式不同。
macro可能会对表达式进行多次运算,而inline函数仅在表达式传入函数时进行运算。如#define sum(a, b) (a) + (b)和inline func(int a, int b) { return a + b; }分别使用sum(a++)和func(a++, b)进行调用时,前者a++计算了两次,而后者a++仅计算一次。
针对
inline需要注意的是:inline只是建议编译器对函数进行内联展开,编译器并不一定会采纳。- 在支持热补丁的场景下,采用
inline可能是一个bad idea。
参考资料:
- 代码展开的阶段不同。
-
什么是
Segmentation Fault,什么时候会出现,如何避免?参考答案
Segmentation Fault中文译为段错误,出现段错误主要是因为程序访问到无权限访问的内存区域。常见的段错误场景主要有:- 对空指针(NULL/nullptr)或未初始化的指针(指针可能指向无效地址)进行解引用(dereference)
- 数组越界访问
- 对只读区域的内存进行更新或访问无效/无权限的内存区域(如内核态地址空间)
避免段错误可以考虑使用静态代码扫描工具,如PC-lint等,扫描代码是否存在以下问题:
- 指针变量未初始化
- 数组是否可能存在越界访问
参考资料:
-
const int* p,int* const p,const int* const p这三者有什么区别?参考答案
const int* p中const修饰的是*p,即指针p所指的对象。也就是说p的值是可以变化的(指向的地址可以变化),但*p不可以(指向的值不可以变化)。如下:
int main() { int a = 1; int b = 2; const int* p = &a; p = &b; // ok *p = 3; // error return 0; }int* const p中const修饰的是p,即指针p。也就是说p的值是不可以变化的(指向的地址不可以变化),但*p可以(指向的值可以变化)。如下:
int main() { int a = 1; int b = 2; int* const p = &a; *p = 2; // ok p = &b; // error return 0; }const int* const p中const既修饰指针p,也修饰针对所指的地址中的内容*p。即指针p不可变化,且指针所指向的地址中的值*p也不可变化。如下:
int main() { int a = 1; int b = 2; const int* const p = &a; *p = 2; // error p = &b; // error return 0; } -
extern "C"的作用是什么?参考答案
extern C主要用于C++程序中,作用于程序的链接过程。如果接触过C++会知道C++支持函数的重载。即如下C++代码的定义是允许的:int func(int a) { return a + 1; } long func(long b) { return b + 2; } int main() { func(1); // call func(int a) func(1L); // call func(long b) return 0; }为支持重载功能,编译器在解析函数时使用函数名及形参类型改编形成新的函数签名,从而保证两个重载函数拥有不同的符号,该过程称为
name mangling。如上面代码生成的二进制代码中,两个重载函数的实际名称分别为:__Z4funci和__Z4funcl:eric% nm a.out 0000000100003f50 T __Z4funci 0000000100003f60 T __Z4funcl 0000000100000000 T __mh_execute_header 0000000100003f80 T _main U dyld_stub_binder其中
__Z表示该符号名称是被C++编译器改编的,而Z后面的数字4指实际函数名称(func)为4个字符。然而C程序中不支持重载,即函数命名是怎样的,其在二进制中看到的就是怎样的。如下为
func函数在二进制中的符号:eric % nm a.out 0000000100000000 T __mh_execute_header 0000000100003f80 T _func 0000000100003f90 T _main U dyld_stub_binder其中
_func中的前缀_为C语言调用约定(C calling convention)要求。因此,若要在C++程序中调用C代码,就需要将被调用函数声明在
extern C中,表示所调用的函数遵循C语言调用约定。否则编译过程会出现符号找不到问题。参考资料:
-
什么是字节对齐(数据结构对齐)?
参考答案
在C语言中,数据结构对齐主要用于结构体定义中。现代CPU在数据结构对齐的前提下可以获得更好的读写效率。数据结构对齐的定义是:
若内存地址`a`是`n`的倍数(其中`n`是2的幂),那么`a`就是n字节对齐的。C程序在x86构架上对不同类型的字节对齐有不同的要求,以64位x86架构为例:
1个char类型(1个字节长度)为`1字节对齐` 1个short类型(2个字节长度)为`2字节对齐` 1个int类型(4个字节长度)为`4字节对齐` 1个long类型(8个字节长度)为`8字节对齐` 1个floag类型(4个字节长度)为`4字节对齐` 1个double类型(8个字节长度)为`8字节对齐` 1个指针类型(8个字节长度)为`8字节对齐`也即如果有如下结构体,其结构体大小在64位x86上应该为
24个字节:struct s { char a; // 1 byte // 1 byte padding short b; // 2 bytes char c; // 1 byte // 3 bytes padding int d; // 4 bytes float e; // 4 bytes double f; // 8 bytes };在上面的结构体中,成员
a是1字节对齐的,而成员b是2字节对齐的,因此在a和b中,会自动添加空白的padding用于保证字节对齐。同理c是1字节对齐的,而d是4字节对齐的,因此在c和d间会自动添加3个padding。如果想修改自动对齐方式,可以在结构体定义前添加
#pragma pack(N),其中N为N字节对齐。如下将struct s修改为1字节对齐后,其结构体大小为20字节:#pragma pack(1) struct s { char a; short b; char c; int d; float e; double f; };参考资料:
-
什么是内存泄漏?
参考答案
C程序中允许使用
malloc等函数在堆上申请内存,这部分内存是需要开发人员自行管理的,若申请的内存一直未释放或无法释放,最后会导致堆可用的空间越来越少,严重的会导致程序崩溃。常见的内存泄漏原因是申请了内存,但内存不再使用后却不释放。如下C代码中申请的内存a在退出函数时未释放,该情境即为内存泄漏场景:void func() { int *t = malloc(1000); }避免内存泄漏主要有以下几种方法:
- 代码检视
- 代码静态扫描工具
- 工具检测,如valgrind
参考资料:
-
大端小端是什么意思?如何判断当前CPU是大端还是小端?
参考答案
大端模式(Big-endian)是指数据的高字节保存在内存的低地址而数据的低字节保存在内存的高地址。大端模式有点类似于字符串的存储方式——内存的地址从低到高,而数据从高到低存放。 小端模式(Little-endian)是指数据的高字节保存在内存的高地址而数据的低字节保存在内存的低地址。 之所以存在大小端模式,是因为我们的内存中每个地址单位对应一个字节(即8bit),但C语言中的
short类型、int类型等是由多个字节组成的,对于16bit及以上的CPU来说,在处理这类多字节类型时就存在字节的组织问题。 要判断CPU使用大端还是小端可以直接解析short类型中低地址的值是高字节还是低字节,代码如下:#include <stdio.h> int main() { short a = 1; printf("a is %s\n", *((char*)&a) == 0x1 ? "little-endian" : "big-endian"); return 0; }需要注意的是,不同的架构可能使用不同的大小端模式,如x86架构为小端模式,arm架构默认为小端模式,但也可以切换为大端模式。
参考资料:
-
如何判断两个浮点数是否相等?
参考答案
在C语言中,与浮点数相关的有两种类型:
float及double,前者为单精度类型,后者为双精度类型。(float及double类型的存储方式可参考IEEE标准的规定) 由于浮点数的数据存储方式,在运算过程中可能存在精度问题,如下:#include <stdio.h> int main() { double a = 0.15 + 0.15; double b = 0.10 + 0.20; printf("a(%lf) is %s to b(%lf)\n", a, a == b ? "euqal" : "not euqal", b); return 0; }上面代码的实际运行结果为:
a(0.300000) is not euqal to b(0.300000)在实际程序中,
a和b的二进制表示分别如下:a: 0011 1111 1101 0011 0011 0011 0011 0011 0011 0011 0011 0011 0011 0011 0011 0011 b: 0011 1111 1101 0011 0011 0011 0011 0011 0011 0011 0011 0011 0011 0011 0011 0100我们可以看到,即使
a和b都是0.3,但在小数部分的最后3 bit实际上是有差异的。为了解决这类浮点数的比较问题,我们可以人为规定一个精度,当精度小于某个确定的值后可以近似地认为两个浮点数相等。在标准库的float.h头文件中就提供了精度宏:FLT_EPSILON及DBL_EPSILON分别代表float类型的精度及double类型的精度,修改后的浮点数比较代码如下:#include <stdio.h> #include <float.h> #include <math.h> int main() { double a = 0.15 + 0.15; double b = 0.10 + 0.20; printf("a(%lf) is %s to b(%lf)\n", a, fabs(a - b) < DBL_EPSILON ? "euqal" : "not euqal", b); printBits(a); printBits(b); return 0; }参考资料:
-
typedef和#define的区别?参考答案
#define和typedef均可用于定义类型别名。但其区别有:#define作用于编译过程的预处理阶段而typedef作用于编译阶段typedef仅用于定义类型别名,而#define还可以定义常量、代码块等
参考资料:
-
malloc和free的实现原理?参考答案(答案来源于ChatGpt)
malloc和free是C语言中用于动态内存管理的函数。malloc函数用于在运行时动态分配指定大小的内存块。它的实现原理通常涉及底层的内存分配算法,例如堆(heap)管理。以下是一种常见的实现原理:-
malloc的实现原理:malloc函数接收一个参数,即所需内存块的大小。malloc会在堆中寻找一块足够大的连续内存空间。- 当找到合适的空间后,它会记录该块内存的大小并进行标记,以便稍后的内存释放使用。
- 返回指向该内存块的指针,供程序使用。
-
free的实现原理:free函数接收一个指针参数,即要释放的内存块的起始地址。free会根据传入的指针找到对应的内存块,并将该内存块标记为可用。- 释放的内存块可以被后续的
malloc调用重新分配使用。
实际的
malloc和free实现可能会因操作系统、编译器和特定的堆管理器而有所不同。这些函数的底层实现通常涉及内存分配算法、堆的数据结构和管理机制。需要注意的是,使用
malloc分配的内存需要在不再需要时使用free显式释放,以避免内存泄漏。如果不释放已分配的内存,会导致程序的内存消耗不断增加,最终可能导致系统资源不足的问题。参考资料:
-
-
请解释C语言中的条件语句
if-else和switch-case的用法和区别。参考答案(答案来源于ChatGpt)
if-else用法:if-else语句用于根据一个条件的真假执行相应的代码块。如果条件为真,执行if后面的代码块;如果条件为假,执行else后面的代码块(如果有)switch-case用法:switch-case语句用于根据一个表达式的值,从多个选项中选择一个执行相应的代码块。
区别:
if-else语句用于对条件的真假进行判断。switch-case语句用于对一个表达式的不同取值进行判断。
-
什么是指针数组和数组指针?请解释它们之间的区别。
参考答案
- 指针数组的英文为:
array of pointers,它表示一个元素都是指针类型的数组。 - 数组指针的英文为:
pointers to an array,它表示一个指向数组的指针
- 指针数组的英文为: